


随着科技的发展,大数据在各个领域的应用变得日益广泛,从政府到私营企业,都在利用大数据分析来优化操作、预测趋势和增强用户体验,大数据存储解决方案尤其关键,因为它们不仅需要处理庞大的数据量,还需保证数据的可访问性和安全性,本文将深入探讨现代大数据存储解决方案,并分析其在实际应用中的效益和挑战。

分布式系统与集群技术
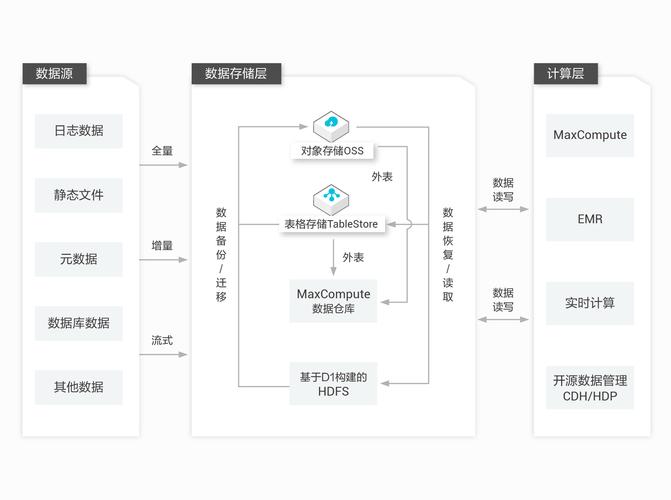
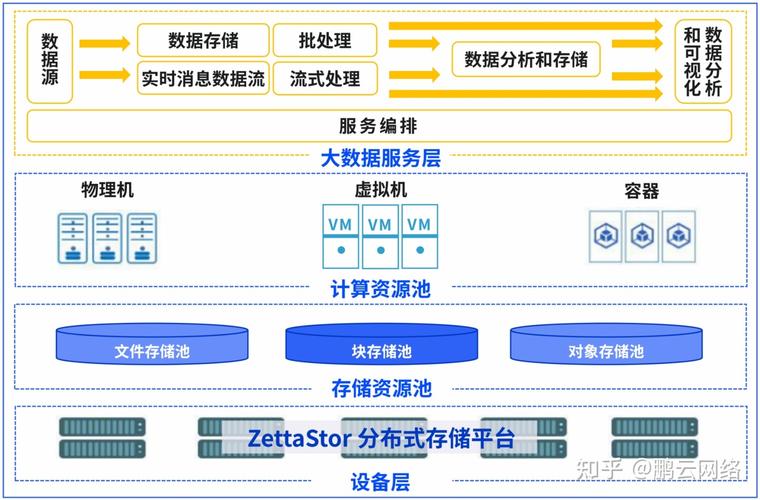
在大数据存储领域,分布式系统和集群技术是基础且核心的组成部分,分布式系统通过将多台服务器集中在一起,并让它们分别负责总体中不同的业务模块,有效解决了传统单体架构难以水平扩展和模块优化的问题,集群技术如利用多台服务器完成相同的业务操作,不仅可以分摊并发压力,还能实现高可用部署,避免单点故障的风险,大型网站如新浪网微博就采用了这种技术来处理海量的访问请求。
NoSQL数据库系统
NoSQL数据库提供了另一种高效的数据存储和处理方法,特别适合处理大量非结构化或半结构化的数据,与传统的关系型数据库相比,NoSQL系统在扩展性和灵活性上具有明显优势,它们能够更好地适应数据的快速变化并且支持更加灵活的数据模型设计,这使得NoSQL数据库在社交媒体、实时数据分析等领域得到了广泛应用。
分布式文件系统
分布式文件系统如HDFS是设计用来存储和管理大规模数据集的文件系统,特别适合于大规模的数据处理任务,HDFS 通过在多个服务器节点之间分配数据存储,可以提高数据的可靠性和系统的总吞吐量,这种系统特别适合于需要处理PB级别数据的应用场景,比如互联网档案馆和大型科学研究项目。
对象存储与云服务
对象存储系统(如AWS S3)为存储和检索大量的非结构化数据提供了一种简便的方式,结合云计算平台的使用,可以实现计算与存储的分离,极大地提高了资源的弹性伸缩能力,并通过数据冷热分层技术降低了存储成本,这对于需要处理海量数据的企业尤为有利,它允许企业按需支付存储资源,而无需前期巨大的硬件投资。
关系型数据库
尽管面临新型存储技术的挑战,传统的关系型数据库仍然在某些场合下发挥着不可替代的作用,特别是在需要复杂查询和事务一致性保障的场景中,关系型数据库提供强大的一致性保证和成熟的查询优化技术,适用于金融、医疗等对数据准确性要求极高的行业。
大数据存储解决方案的选择依据
选择正确的数据存储方案需要考虑多个因素,包括数据的类型、大小、访问频率以及预算等,对于需要频繁读写和快速访问的数据,内存数据库或分布式缓存可能是更好的选择,而对于历史数据的归档,冷存储解决方案则更为经济高效。
上文归纳与展望
大数据存储解决方案的选型是一个复杂但至关重要的任务,从分布式系统到NoSQL数据库,再到分布式文件系统和对象存储,每种技术都有其独特的优势和适用场景,随着技术的不断进步,未来可能会有更多创新的解决方案出现,以应对日益增长的数据存储需求和日趋复杂的应用场景。
相关问答FAQs
Q1: 分布式系统与集群技术有何不同?
A1: 分布式系统强调的是将不同的业务模块分布在不同的服务器上,每台服务器独立负责一部分功能,侧重于功能的分布;而集群技术则是多台服务器共同完成相同的业务,侧重于提升系统的负载能力和高可用性。
Q2: 如何根据业务需求选择适合的数据存储方案?
A2: 首先需要评估数据的类型、大小、结构和访问模式,如果数据结构复杂并且需要事务一致性支持,可能适合使用关系型数据库;如果数据量大且结构不固定,可以考虑使用NoSQL数据库或分布式文件系统;对于需要快速访问的数据,内存数据库或分布式缓存系统可能是更好的选择,也需要考虑成本和技术团队的能力。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/872795.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复