


MapReduce任务调度器与任务调度

在当今大数据时代,处理海量数据已成为企业获取洞见、优化服务和增强决策的关键环节,Hadoop MapReduce作为一种分布式计算框架,通过拆分数据处理过程为多个小任务,能在大规模硬件集群上实现高效的并行处理,在这一过程中,任务调度器扮演着至关重要的角色,它不仅影响作业执行的效率和速度,还直接关系到资源利用的最优化。
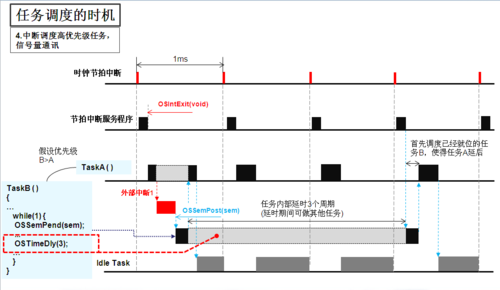
在MapReduce框架中,任务的生命周期始于客户端提交作业,经过资源申请、任务分配、执行直至完成,此过程中,任务调度器(Scheduler)负责将任务分配到各个节点,并根据集群的实时状态做出最佳调度决策。
任务调度的类型:
1、先进先出调度器(FIFO Scheduler):
最早的Hadoop版本所使用的简单调度算法。
按照作业提交的顺序来执行,不支持多队列和优先级等高级特性。
2、计算能力调度器(Capacity Scheduler):
由Yahoo贡献,针对多用户共享集群环境设计。
允许多个队列,每个队列可设置一定比例的资源,确保最小资源共享。
3、公平调度器(Fair Scheduler):
旨在确保所有作业平均共享资源。
支持延迟调度,可根据作业的运行时间调整其优先级。
4、动态优先级调度器:
根据系统当前的负载动态调整作业优先级。
优化资源使用率,减少作业的完成时间。
调度流程详解:
1、资源申请与分配:
当一个MapReduce程序被提交后,YarnRunner首先会向ResourceManager申请应用资源。
ResourceManager返回必要的资源路径,以便程序能将运行所需的资源提交到HDFS上。
2、任务初始化与分配:
ResourceManager接收到运行mrAppMaster的请求后,将用户的请求初始化成一个或多个Task任务。
根据调度策略,选择合适的NodeManager来领取并执行这些Task任务。
3、任务执行与监控:
NodeManager在被分配的Container中启动MRAppmaster和具体的Map或Reduce任务。
在整个执行过程中,调度器持续监控任务的运行状态,并根据需要进行调整。
关键要素分析:
1、推测执行机制:
为了处理可能的任务执行延迟,调度器会启动备份任务以加速整体进度。
这要求调度器具有高效的判断机制,识别哪些任务需要启动备份。
2、任务和节点间的匹配:
调度器必须考虑节点的当前负载、剩余资源以及网络位置等因素。
合理安排Map和Reduce任务,避免出现资源瓶颈。
常见问题及解决策略:
1、任务失败恢复:
定期检查任务执行状态,一旦发现失败立即重新调度。
提供容错机制,如数据块副本和任务重试策略。
2、资源利用优化:
实施容器复用策略,减少因任务启动和停止造成的资源浪费。
根据作业的重要性和紧迫性动态调整资源分配。
MapReduce任务调度器在数据处理的整个生命周期中发挥着核心作用,通过选择合适的调度策略,可以显著提高资源的利用率和作业执行效率,面对不同的使用场景和需求,合理配置和优化调度器是提升Hadoop集群性能的关键所在。
FAQs
Q1: 如何选择适合的MapReduce任务调度器?
A1: 选择适合的调度器主要取决于你的具体需求和集群的使用情况,如果集群需要服务于多个用户或组织,考虑使用计算能力调度器或公平调度器,它们支持多队列管理,能够更好地平衡不同用户的需求,对于单用户或单一业务的集群,先进先出调度器可能更简单高效。
Q2: 如何优化MapReduce任务的调度?
A2: 优化任务调度主要包括以下几个方面:一是合理配置调度器参数,根据作业的特性(如优先级、资源需求)调整;二是监控和分析作业运行数据,找出性能瓶颈;三是采用推测执行等技术减少作业完成时间;四是及时更新和升级Hadoop版本,利用最新的改进和功能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/872734.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复