


在大数据时代,MongoDB作为一款流行的NoSQL数据库,其MapReduce功能为处理大规模数据集提供了强大的支持,MapReduce是一个编程模型,用于大规模数据处理,在MongoDB中,MapReduce可以并行处理数据,尤其在数据导入和导出时,这种并行处理能力极大提高了效率,本文将深入探讨MongoDB的MapReduce并行处理机制及其在数据导入方面的应用。

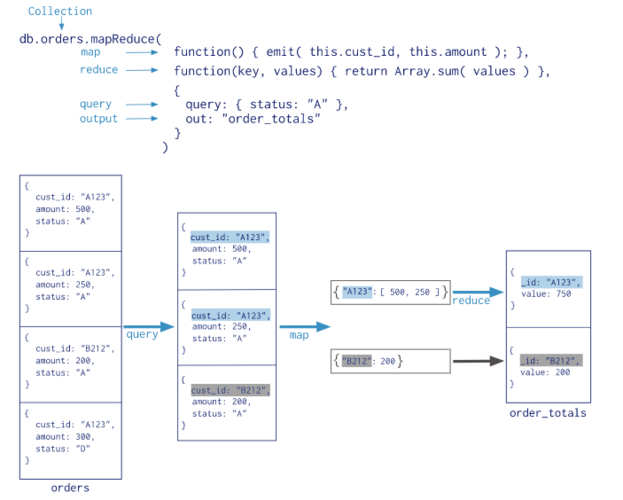
MongoDB中的MapReduce操作分为几个阶段,包括Map、Shuffle、Reduce和Finalize,Map阶段是将操作应用到集合的每一个文档上,Shuffle阶段则是根据Key分组文档,并为每个不同的Key生成一系列的值表,Reduce阶段处理这些值表,直到每个Key只对应一个值表,且此值表中只有一个元素,这就是MapReduce的结果,Finalize阶段是可选的,它用于在得到最终结果后进行一些数据“修剪”性质的处理。
MapReduce的优势在于其能够分布式地执行复杂的数据处理任务,在MongoDB中,这意味着可以在多个服务器上同时运行MapReduce操作,这对于处理大型数据集尤其有用,当使用MapReduce进行数据导入时,可以显著减少处理时间,因为数据可以在多个节点上并行处理。
MapReduce在MongoDB中的并行查询方面也显示出了其独特的优势,基于MongoDB的分布式存储,MapReduce能够高效地执行查询操作,尤其是在涉及大量数据的情况下,通过将查询操作分布到多个节点上,MapReduce不仅提高了查询速度,还保持了系统的高可用性和伸缩性。
在使用MongoDB的MapReduce进行并行导入时,有几个关键因素需要考虑,确保硬件资源足够支持并行操作,合理设计Map和Reduce函数以最大化效率和避免不必要的计算,适当配置MongoDB以优化并行处理性能,包括设置合适的索引和调整服务器参数。
归纳而言,MongoDB的MapReduce功能为并行数据处理提供了强大的支持,特别是在数据导入和查询方面,通过合理利用这一功能,可以有效提高数据处理的速度和效率,满足现代大数据处理的需求,随着技术的不断发展,期待看到更多创新的应用,以进一步发挥MongoDB在数据密集型任务中的潜力。
FAQs
1. MongoDB中MapReduce与Aggregate框架有何不同?
MapReduce提供了一种编程模型,允许用户通过编写Map和Reduce函数来处理数据,这适用于复杂且灵活的数据处理任务,尤其是当内置的聚合操作无法满足需求时,而Aggregate框架则提供了一套丰富的聚合操作符,可以执行各种数据处理操作,通常在性能上优于MapReduce,因为它使用内部优化的管道操作,选择使用哪一个取决于具体的数据处理需求和性能考虑。
2. 如何优化MongoDB中的MapReduce操作?
确保输入数据集的大小合适,避免单个文档过大导致内存使用过多,在Map和Reduce函数中尽量避免复杂的操作和数据转换,以减少处理时间,使用合适的硬件资源,如足够的内存和高速磁盘,考虑在Reduce阶段使用多线程或并行处理,以进一步提高性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/872478.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复