


在大数据生态系统中,MapReduce和Hive是处理大规模数据集的关键组件,与这些技术相关的进程故障可能会导致数据处理任务的延误或失败,下面将详细分析MapReduce和Hive(特别是HiveServer和HiveHCat)进程故障的原因及解决方案,并提供相应的建议以预防此类问题的发生,具体分析如下:
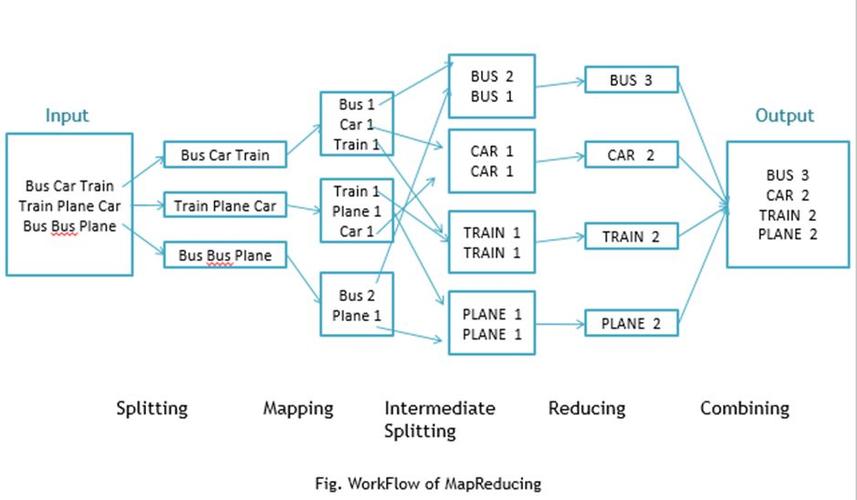

1、MapReduce进程故障
资源分配问题:MapReduce作业可能会因为资源不足而失败,这包括内存溢出、磁盘空间不足或网络带宽限制,优化资源分配和监控资源使用情况对于避免此类故障至关重要。
配置错误:错误的MapReduce配置,如不当的输入输出格式、错误的压缩代码或者不匹配的访问权限设置,都可能导致进程故障,定期审查和测试配置是必要的步骤。
代码缺陷:MapReduce作业的代码缺陷,比如逻辑错误或者编程错误,可以引起进程异常,代码审查和单元测试是提高代码质量的有效方法。
2、HiveServer进程故障
配置文件解析错误:如所述,HiveServer在解析mapredsite.xml配置文件时遇到错误,导致进程无法正常启动,解决这一问题需要检查配置文件的语法和内容,确保其正确性。
日志文件分析:在HiveServer的日志文件中查找错误信息是诊断问题的关键步骤,特别注意错误信息,如“Premature end of file”,这可能指示配置文件损坏或不完整。
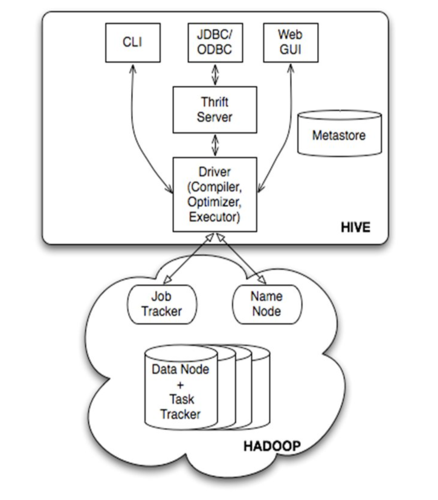
依赖服务故障:HiveServer依赖于其他服务,如HDFS和YARN,这些服务的故障可能影响HiveServer的运行,监控这些服务的健康状况对维持HiveServer的稳定性至关重要。
3、HiveHCat进程故障
网络连接问题:WebHCat 是通过HTTP接口暴露Hive功能的模块,网络连接问题(如超时或连接丢失)可能导致故障,确保网络稳定性和连接可靠性是解决这一问题的关键。
权限和认证问题:HiveHCat的权限配置错误或认证问题可能导致进程故障,正确配置权限和认证机制是保障HiveHCat正常运行的重要环节。
会话管理不当:HiveHCat管理多个用户会话,不当的会话管理可能导致资源竞争或死锁,合理控制并发会话数量和生命周期有助于避免此类问题。
4、故障恢复与重启策略
重启故障进程:在许多情况下,尝试重启故障的MapReduce、HiveServer或HiveHCat进程可以作为快速解决问题的方法,如果问题持续存在,则需深入分析原因。
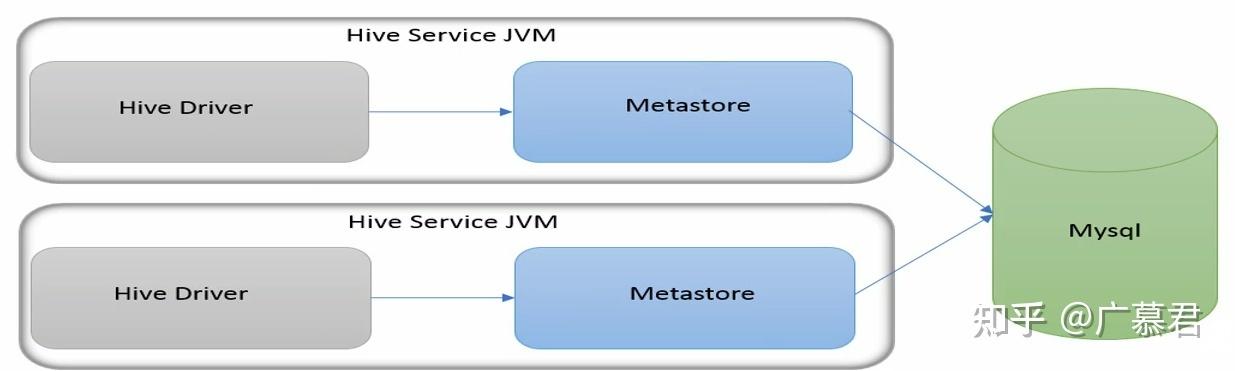
自动化故障恢复:实现自动化故障检测和恢复机制,可以减少人工干预的需要,并加快故障恢复速度。
5、监控与预警
实时监控:部署实时监控系统,如Ganglia或Nagios,可以及时发现并通知有关故障,从而缩短修复时间。
预警系统:结合历史数据分析,建立预警系统预测潜在的故障风险,提前采取预防措施。
6、性能优化
数据组织优化:如所述,采用MapReduce进行ETL处理后再由Hive进行分析,可以提高处理效率,合理的数据组织和处理流程设计对提升性能至关重要。
资源调度优化:优化Hadoop集群的资源调度策略,确保高优先级的任务能够及时获取足够资源。
7、版本兼容性与更新
软件版本控制:保持MapReduce和Hive的版本兼容性,避免因版本差异引起的故障,定期应用软件更新和补丁也是维护稳定性的重要方面。
通过上述详细分析,人们可以看到MapReduce和Hive进程的故障涉及多方面的因素,从资源配置到网络连接,再到服务依赖关系等,每个环节都可能成为导致故障的潜在原因,建立一个全面的监控和预警系统,以及实施有效的故障恢复和优化策略,对于确保这些关键进程的稳定运行至关重要,考虑到HiveServer和HiveHCat的特殊性,加强日志管理和配置文件的维护也是防止故障的必要措施。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/872462.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复