


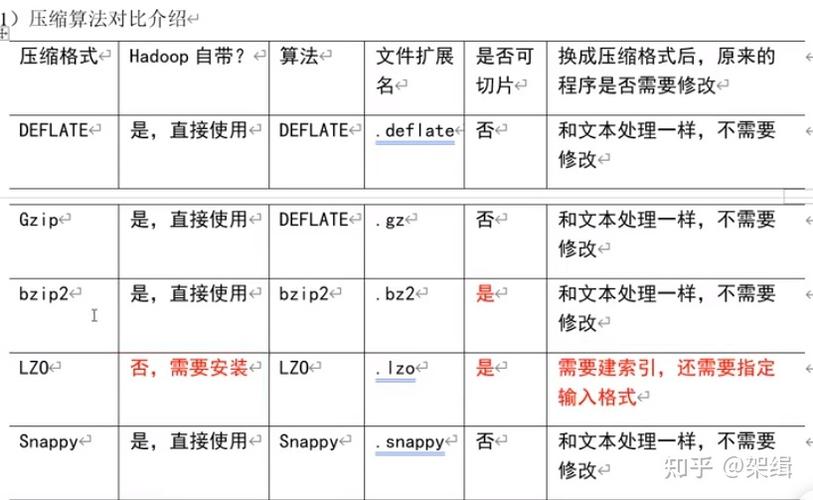
当使用MapReduce读取Snappy压缩文件时,可能会遇到一些错误,以下是一些常见的问题和解决方法:
1. 缺少Snappy库
问题描述: 在运行MapReduce任务时,出现类似于“找不到或无法加载主类org.apache.hadoop.io.compress.SnappyCodec”的错误。
解决方案: 确保Hadoop集群中的所有节点都安装了Snappy库,并且库的路径已正确配置,可以在$HADOOP_HOME/etc/hadoop/coresite.xml文件中添加以下配置来指定Snappy库的路径:
<property> <name>io.compression.codecs</name> <value>org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec</value> </property>
2. 不支持的文件格式
问题描述: 在尝试读取Snappy压缩文件时,出现类似于“不支持的文件格式”的错误。
解决方案: 确保输入文件是有效的Snappy压缩文件,并且文件扩展名与实际内容匹配,如果文件不是Snappy压缩的,需要先将其解压缩为文本或其他支持的格式。
3. 输入路径错误
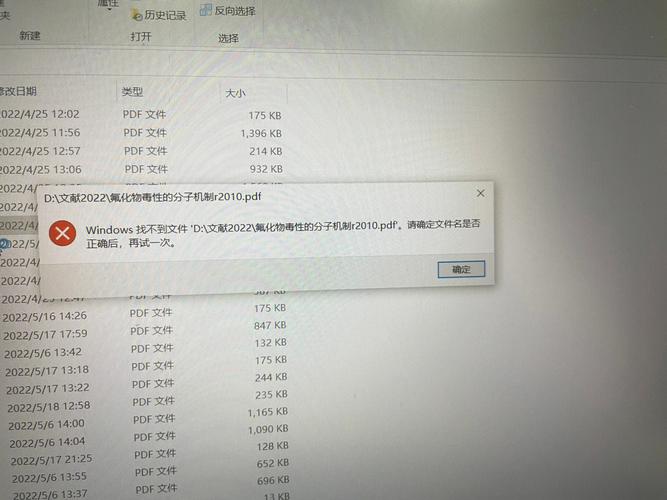
问题描述: 在运行MapReduce任务时,出现类似于“无法访问文件”或“找不到文件”的错误。
解决方案: 检查输入文件的路径是否正确,确保路径中的目录存在,并且文件名拼写正确,可以使用HDFS命令行工具(如hdfs dfs ls)来验证文件是否存在于指定的路径。
4. 权限问题
问题描述: 在尝试读取Snappy压缩文件时,出现类似于“权限不足”的错误。
解决方案: 确保运行MapReduce任务的用户具有足够的权限来访问输入文件,可以使用hdfs dfs chmod命令更改文件的权限,
hdfs dfs chmod 755 /path/to/your/input/file
这将允许所有用户对文件进行读、写和执行操作。
5. 代码错误
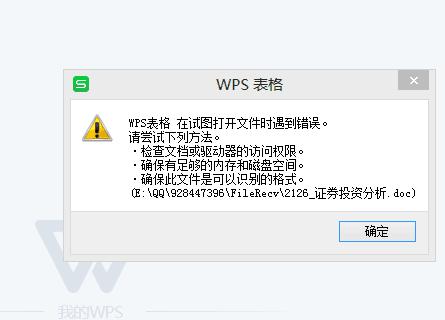
问题描述: 在编写MapReduce程序时,出现其他类型的错误,如语法错误、逻辑错误等。
解决方案: 仔细检查代码,确保没有语法错误或逻辑错误,可以参考官方文档或相关教程来了解如何正确编写MapReduce程序,确保使用了正确的输入格式和输出格式。
解决MapReduce读取Snappy文件的问题通常涉及到检查环境配置、文件格式、路径和权限等方面,根据具体的错误信息,可以采取相应的解决方案来解决问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/872322.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复