


python,set1 = {1, 2, 3, 4},set2 = {3, 4, 5, 6},intersection = set1.intersection(set2),print(intersection) # 输出:{3, 4},“在大数据时代,处理大规模数据集已成为一种常态,MapReduce模型应运而生,由谷歌提出并广泛应用于海量数据处理中,Python作为数据科学领域的热门语言,其与MapReduce框架的结合使用为数据处理提供了便捷与高效,本文旨在深入探讨如何使用Python实现MapReduce编程模型下的集合交集操作。

MapReduce模型基础
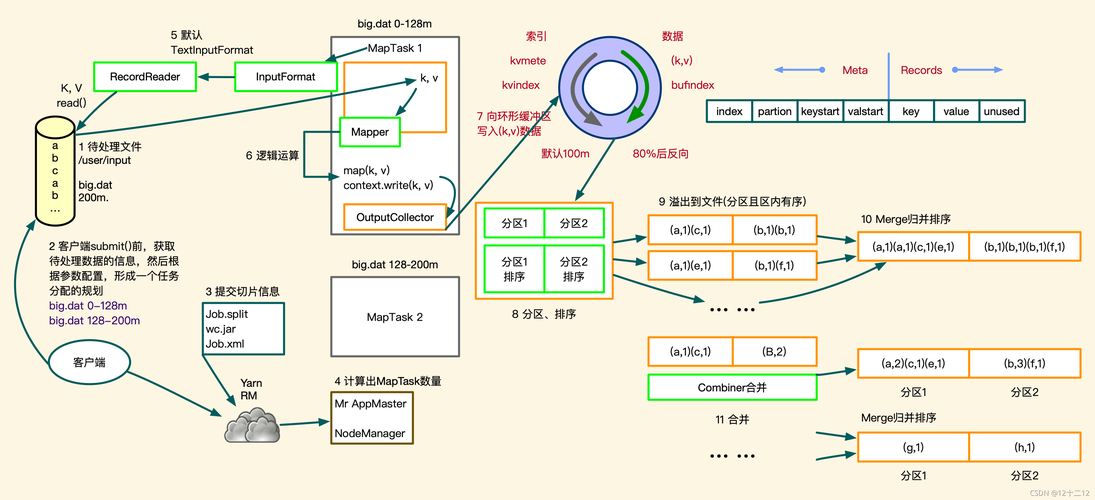
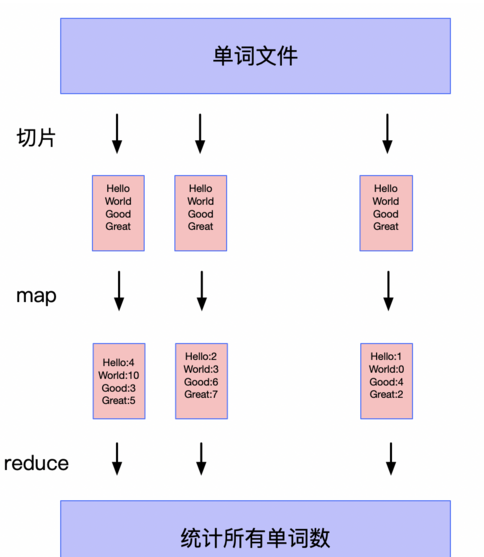
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它主要包含两个阶段:Map阶段和Reduce阶段,在Map阶段,输入数据集被分割成小块,由多个Map任务并行处理,每个Map任务会处理分配给它的数据,生成一系列中间(key, value)对,而在Reduce阶段,这些中间结果会按照key值进行重新分组和排序,具有相同key值的结果会被传递到同一个Reduce任务,每个Reduce任务将负责对这部分数据进行归约操作,生成最终的结果。
Python中的MapReduce实现
Python中实现MapReduce任务通常依赖于Hadoop Streaming或类似的框架,使得可以在Hadoop集群上运行Python脚本,具体到编写MapReduce任务时,需要分别实现Mapper和Reducer两个部分的脚本。
1.编写Mapper脚本
在Mapper阶段,主要工作是对输入数据进行处理,生成一系列(key, value)对,若要计算两个集合的交集,可以设计Mapper输出的key为元素本身,value为该元素所属的集合标识,这样设计可以确保在Reduce阶段能够根据key值(即元素)将不同集合中的相同元素聚集在一起。
2.编写Reducer脚本
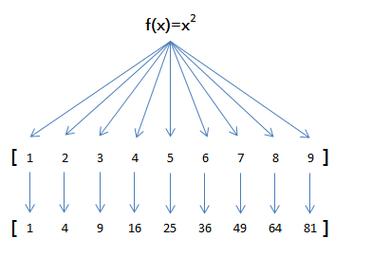
到了Reducer阶段,根据key值(元素)对value(集合标识)进行汇总,在交集操作的场景下,如果某元素出现在所有指定的集合中,则该元素应当被包含在交集中,Reducer脚本中需要对每个key的所有value进行检查,以确定是否所有的集合标识都出现,如果是,则输出该元素作为交集的一部分。
集合交集操作实例
为了更加深入理解如何使用MapReduce实现集合交集,假设有两个集合A和B,需要找到它们的交集,在Mapper阶段,可以设计输出的key为集合中的元素,value为集合标识(A’或’B’),在Reducer阶段,对于每个元素,检查其对应的集合标识是否同时包含’A’和’B’,如果是,则说明该元素属于集合A和B的交集。
通过上述过程,即可利用MapReduce模型及Python脚本实现集合的交集操作,这一过程不仅展示了MapReduce在处理大数据问题上的潜力,也体现了Python在大数据处理方面的灵活性和强大功能。
相关问答FAQs
Q1: 如何在Hadoop集群上运行Python的MapReduce任务?
A1: 确保你的Hadoop集群已经正确安装并运行,在Python中编写你的Mapper和Reducer脚本,使用Hadoop Streaming工具,可以通过命令行提交你的任务到Hadoop集群,具体命令可能类似于hadoop jar hadoopstreaming.jar file mapper.py mapper mapper.py file reducer.py reducer reducer.py input /path/to/input output /path/to/output,这里,mapper.py和reducer.py是你的Python脚本文件,/path/to/input是HDFS上的输入路径,而/path/to/output是结果存储的HDFS路径。
Q2: 在编写MapReduce脚本时,如何处理自定义的数据格式?
A2: 处理自定义数据格式时,关键在于Mapper阶段的实现,你可以在Mapper脚本中使用Python强大的数据处理能力来解析输入数据,如果你的数据是JSON格式,可以使用Python的json库来解析输入数据,并提取出你关心的部分作为(key, value)对输出,同样地,对于CSV、XML等其他格式,也有相应的Python库可以帮助你完成数据的解析和转换,在编写Reducer时,同样可以根据需要处理的key和value的类型和结构,进行合理的归约操作。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/871727.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复