


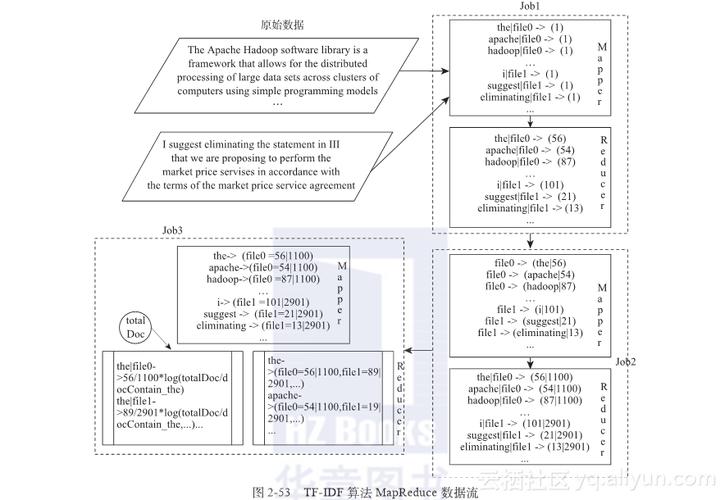
MapReduce是一个编程模型,用于处理和生成大数据集。在文本分析中,TFIDF(词频逆文档频率)是一种统计方法,用于评估一个词语对于一个文档集或一个语料库中的一份文档的重要性。通过使用MapReduce实现TFIDF,可以高效地并行计算大量文本数据中的TFIDF值,从而快速提取关键词并评估文本的重要性。
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,TFIDF(Term FrequencyInverse Document Frequency)是一种统计方法,用于评估一个词对于一个文件集或一个语料库中的一份文件的重要程度。


(图片来源网络,侵删)
以下是使用MapReduce实现TFIDF的步骤:
1、Map阶段:计算每个文档中每个词的词频(TF)。
2、Reduce阶段:计算每个词的逆文档频率(IDF),并结合Map阶段的输出来计算每个文档中每个词的TFIDF值。
Map阶段
输入
文本文件集合,每个文件包含一系列的单词。
输出
(图片来源网络,侵删)
键值对,键是单词,值是一个元组,其中第一个元素是文档ID,第二个元素是该单词在该文档中出现的次数。
def map(key, value):
# key: document ID
# value: text of the document
words = value.split()
for word in words:
emit(word, (key, 1)) Reduce阶段
输入
Map阶段的输出,即单词及其在各个文档中的出现情况。
输出
键值对,键是单词,值是一个元组,其中第一个元素是总文档数,第二个元素是包含该单词的文档数。
def reduce(key, values):
# key: word
# values: list of tuples (document_id, count)
total_docs = set()
for doc_id, count in values:
total_docs.add(doc_id)
emit(key, (len(total_docs), sum(count for _, count in values))) 计算TFIDF
(图片来源网络,侵删)
输入
Reduce阶段的输出,即每个单词的总文档数和包含该单词的文档数。
输出
键值对,键是单词,值是该单词的TFIDF值。
def calculate_tfidf(key, value):
# key: word
# value: (total_docs, count_in_current_doc)
total_docs, count_in_current_doc = value
tfidf = count_in_current_doc * math.log(total_docs / count_in_current_doc)
emit(key, tfidf) 上述代码片段仅为伪代码,实际实现时需要根据具体的MapReduce框架进行调整,Hadoop MapReduce框架中的emit函数应替换为context.write,还需要设置适当的输入和输出路径,以及可能需要的其他配置参数。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/871363.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复