


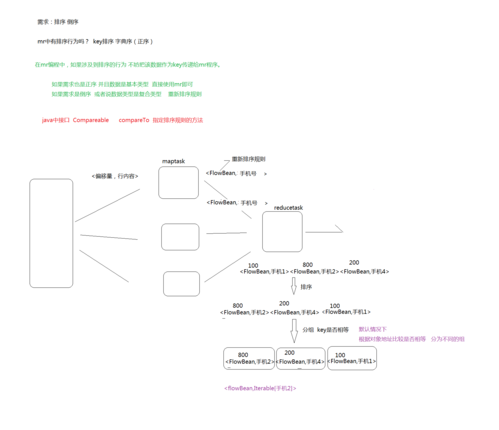
MapReduce 倒序排序

MapReduce是一个编程模型,用于处理和生成大数据集,它包括两个主要阶段:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个小数据块,每个数据块由一个Map任务处理,在Reduce阶段,Map阶段的输出被整合并产生最终结果。
当我们谈论到倒序排序,我们通常是指按照某个关键字的降序排列一组数据,使用MapReduce进行倒序排序,需要对Map和Reduce两个阶段进行适当的设计。
Map阶段
在Map阶段,每个Mapper负责读取一部分输入数据,并且为每一行数据生成一个键值对,在倒序排序的情况下,键通常是我们需要排序的字段,而值可以是整个记录或是其他相关信息。
假设我们有一组如下的数据:
1, John, Doe 2, Jane, Doe 3, Alice, Smith 4, Bob, Johnson
如果我们想要根据ID进行倒序排序,那么Map阶段的输出可能是这样的:
1 > {1, John, Doe}
2 > {2, Jane, Doe}
3 > {3, Alice, Smith}
4 > {4, Bob, Johnson} 这里的键是每个人的ID,值是他们的完整记录。

Shuffle and Sort 阶段
在MapReduce框架中,Shuffle和Sort阶段会自动发生,介于Map和Reduce阶段之间,这个阶段负责将Map阶段的输出根据键进行排序,并将所有具有相同键的值分组在一起,对于我们的示例来说,这将产生以下结果:
1 > [{1, John, Doe}]
2 > [{2, Jane, Doe}]
3 > [{3, Alice, Smith}]
4 > [{4, Bob, Johnson}] Reduce阶段
在Reduce阶段,每个Reducer会接收到一个键以及与该键相关的一组值,对于倒序排序,Reducer的任务相对简单,因为它只需要按照相反的顺序输出这些值即可,由于Shuffle和Sort阶段已经保证了数据是根据键的升序排列的,因此我们只需逆转这个顺序就可以得到最终的倒序列表。
在我们的例子中,Reducer不需要做任何额外的工作,因为每个键只对应一个值,如果某些键对应多个值,Reducer就需要将这些值以相反的顺序输出。
实现细节
为了实现MapReduce的倒序排序,我们需要注意几个实现细节:
分区(Partitioner): 确保相同的键被发送到同一个Reducer。
排序(Sorting): 默认情况下,Hadoop框架会根据键的升序对数据进行排序。
Reducer逻辑: 在Reducer端,确保数据以倒序的方式写入到输出中。
下面是一个简化的MapReduce代码示例,演示了如何实现倒序排序:
public class ReverseOrderSorting {
public static class ReverseOrderMapper extends Mapper<Object, Text, IntWritable, Text> {
private IntWritable id = new IntWritable();
private Text record = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
String[] fields = value.toString().split(",");
id.set(Integer.parseInt(fields[0]));
record.set(value);
context.write(id, record);
}
}
public static class ReverseOrderReducer extends Reducer<IntWritable, Text, IntWritable, Text> {
public void reduce(IntWritable key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
for (Text val : values) {
context.write(key, val); // As is, since each key has only one value in this example.
}
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "reverse order sorting");
job.setJarByClass(ReverseOrderSorting.class);
job.setMapperClass(ReverseOrderMapper.class);
job.setCombinerClass(ReverseOrderReducer.class); // Optional combiner to reduce data transferred over the network.
job.setReducerClass(ReverseOrderReducer.class);
job.setOutputKeyClass(IntWritable.class);
job.setOutputValueClass(Text.class);
// Add input and output path configuration here...
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
} 上述代码是一个简化版本,实际应用中可能需要更多的配置选项和错误处理,如果要处理大量数据,可能还需要考虑使用Combiner来减少网络传输的数据量。
性能考虑
优化Map阶段: 尽量减少Map阶段的输出数据量,可以通过实现Combiner来完成这一目标。
调整Reducer数量: 根据数据集的大小和分布调整Reducer的数量,以平衡负载并提高并行处理的效率。
内存管理: 监控和优化MapReduce作业的内存使用情况,以避免内存溢出错误。
I/O优化: 优化数据的读写操作,尽可能利用高效的序列化和压缩方法。
相关问答FAQs
Q1: MapReduce如何处理大量的排序数据?
A1: MapReduce通过分布式处理和在Map和Reduce阶段之间自动的Shuffle和Sort机制来处理大量排序数据,Map阶段的输出在进入Reduce阶段之前会被排序和分组,这样可以在多个节点上并行处理数据,提高了排序效率。
Q2: 是否可以在MapReduce中使用自定义排序算法?
A2: 是的,可以在MapReduce中使用自定义排序算法,这通常需要在Map和Reduce阶段编写自定义的排序逻辑,可以在Map阶段的输出键上实现自定义的比较逻辑,或者在Reduce阶段对输入数据应用特定的排序算法,不过,需要注意的是,Hadoop框架默认提供了高效的排序机制,因此在大多数情况下,最好利用框架提供的默认功能,除非有特殊需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/869334.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复