


MapReduce是一个编程模型,用于处理和生成大数据集。它包括两个主要阶段:Map阶段将任务分解成小块并行处理,而Reduce阶段则将结果合并输出。本代码样例展示了如何实现MapReduce的统计功能,如计数或求和。
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个阶段组成:Map阶段和Reduce阶段,下面是一个使用Java编写的MapReduce抽象类示例代码,用于统计文本中的单词频率。
(图片来源网络,侵删)
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> { private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
这个示例代码包含了以下几个部分:
1、TokenizerMapper类:继承自Mapper类,用于将输入文本分割成单词,并为每个单词输出一个键值对(单词,1)。
2、IntSumReducer类:继承自Reducer类,用于将相同单词的计数相加,得到每个单词的总计数。
3、main方法:设置作业配置,包括输入输出路径、Mapper和Reducer类等,并提交作业。
要运行这个示例代码,你需要将其保存为WordCount.java文件,然后使用Hadoop命令行工具编译和运行它。
$ hadoop com.sun.tools.javac.Main WordCount.java $ jar cf wc.jar WordCount*.class $ hadoop jar wc.jar WordCount input output
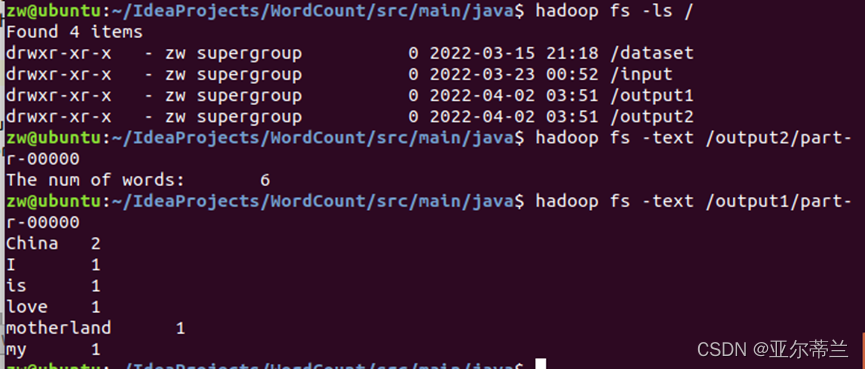
input是包含文本数据的HDFS目录,output是结果输出的HDFS目录。
(图片来源网络,侵删)
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/869290.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复