


MapReduce 是一种编程模型,用于处理和生成大数据集。它包括两个主要阶段:Map 阶段,将输入数据分成小块并处理每一块;Reduce 阶段,汇总 Map 输出的结果。这种模型适合并行处理,常用于分布式系统。
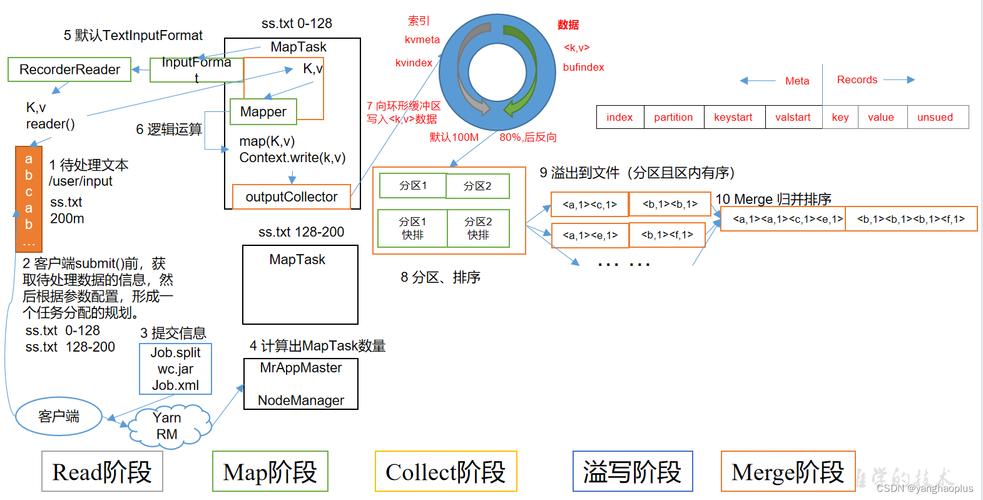
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要步骤组成:Map(映射)和Reduce(归约),下面是一个详细的MapReduce分析表格:

(图片来源网络,侵删)
| 阶段 | 描述 |
| Map | 在这个阶段,输入数据被分割成多个独立的块,然后每个块被一个map函数处理,Map函数接收输入数据并产生中间键值对,这些键值对会被分配给不同的reduce任务。 |
| Shuffle | 在这个阶段,所有map任务产生的中间键值对会根据键进行排序和分组,以便相同的键可以一起传递给同一个reduce任务,这个过程称为shuffle。 |
| Reduce | Reduce阶段接收来自map阶段的中间键值对,并对具有相同键的所有值应用reduce函数,Reduce函数将中间键值对聚合成一个或多个输出结果。 |
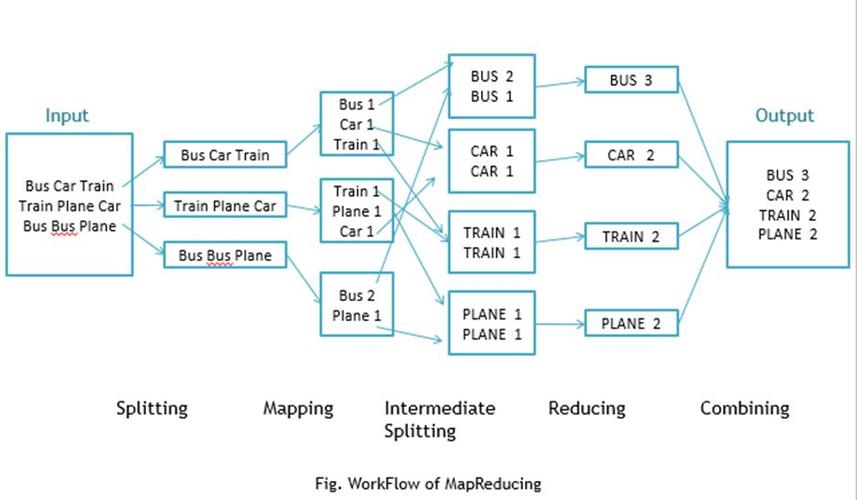
下面是一个简单的MapReduce示例代码:
Mapper function
def mapper(input_data):
# Split the input data into words
words = input_data.split()
# Emit each word with a count of 1
for word in words:
yield (word, 1)
Reducer function
def reducer(key, values):
# Sum up the counts for each word
total_count = sum(values)
# Emit the word and its total count
yield (key, total_count)
Example usage
if __name__ == "__main__":
# Sample input data
input_data = "hello world hello mapreduce"
# Apply the mapper function to the input data
map_results = list(mapper(input_data))
print("Map results:", map_results)
# Group the map results by key (word)
grouped_results = {}
for key, value in map_results:
if key not in grouped_results:
grouped_results[key] = []
grouped_results[key].append(value)
# Apply the reducer function to the grouped results
reduce_results = list(reducer(key, grouped_results[key]) for key in grouped_results)
print("Reduce results:", reduce_results) 在这个示例中,我们首先定义了一个mapper函数,它将输入文本分割成单词,并为每个单词生成一个键值对(单词,1),我们定义了一个reducer函数,它将具有相同键的值相加,以计算每个单词的出现次数,我们使用这两个函数来处理示例输入数据,并打印出映射和归约的结果。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/869021.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复