


爬虫技术解析


网络爬虫的定义与重要性
在大数据时代,互联网中的数据量是海量的,为了自动高效地获取这些信息,网络爬虫应运而生,简而言之,网络爬虫是一种自动化程序,用于从互联网上获取数据,它通过模拟浏览器行为,访问指定的网页,并从中提取所需的信息,这种技术不仅对于搜索引擎至关重要,同时也为数据挖掘和大数据分析提供了基础支持。
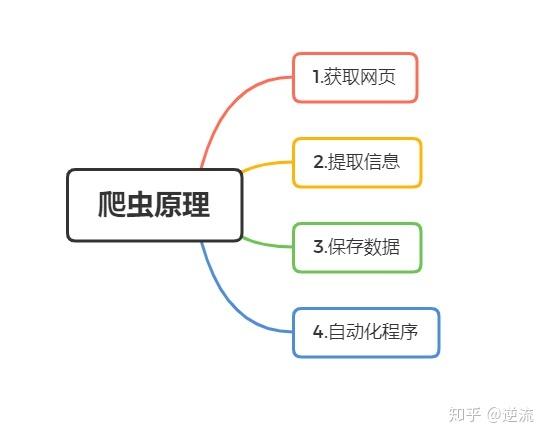
网络爬虫的类型与工作原理
1、通用网络爬虫: 这类爬虫的目标是尽可能多地爬取高质量网页,百度蜘蛛(Baiduspider)就是这样一种爬虫,它每天在海量的互联网信息中进行爬取,爬取优质信息并收录,以供用户检索使用。
2、聚焦网络爬虫: 这类爬虫根据特定的需求和检索条件,有目的地爬取信息,它需要过滤掉一些无用信息,只保留那些符合特定需求的数据。
3、增量式网络爬虫: 这种爬虫能够识别出已变更或更新的网页,并对这部分内容进行再次爬取。
4、深层网络爬虫: 它们可以访问并爬取那些普通搜索引擎难以到达的深层次网页信息。
网络爬虫算法的重要性
网络爬虫的效率和效果很大程度上取决于其背后的算法设计,百度蜘蛛爬虫的算法决定了如何覆盖互联网中的更多优质网页以及如何筛选重复页面,这些算法的设计需要兼顾效率和准确性,以确保爬取的数据既全面又符合需求。
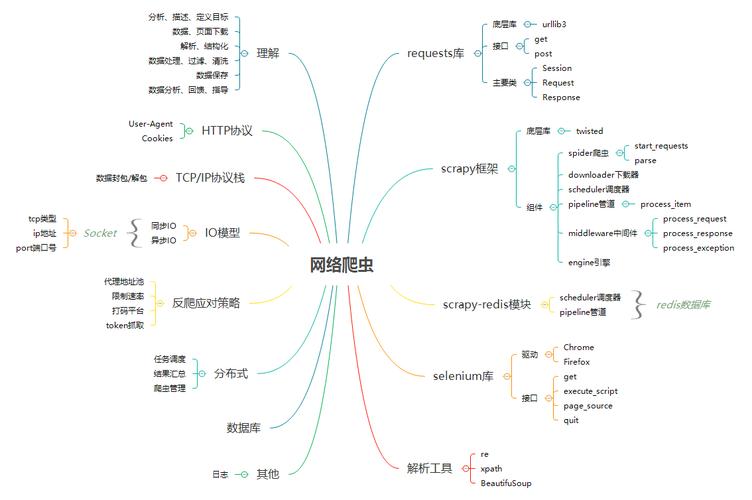
爬虫技术的实现
使用Python编写爬虫程序是一种常见的实践,Python提供了丰富的库支持,如BeautifulSoup和Scrapy,这些工具可以极大地简化爬虫的编程过程,通过编写脚本,设置爬取逻辑和数据提取规则,可以实现高度定制化的数据收集。
相关案例分析
以某电商网站为例,通过聚焦网络爬虫技术,可以从多个竞争对手网站上实时监控和抓取产品价格变化,从而为定价策略提供数据支持,新闻聚合网站利用通用网络爬虫持续收集全球各地的最新新闻报道,为用户提供及时的信息更新。
相关问题与解答
Q1: 网络爬虫是否合法?
A1: 网络爬虫的合法性取决于其遵守的规则,尊重网站的robots.txt文件和使用合理的爬取频率是基本的法律要求,数据的使用和分发也需符合相关的法律法规。
Q2: 爬虫技术未来的发展趋势是什么?
A2: 随着人工智能和机器学习技术的发展,未来网络爬虫将更加智能化,能更准确地理解网页内容和用户意图,同时提升数据处理的效率和精确度。
归纳而言,网络爬虫作为获取互联网数据的重要工具,在许多领域内发挥着不可或缺的作用,了解其类型、工作原理及实现方式,有助于我们更好地利用这一技术,推动数据驱动的决策和发展。
常见问题解答
Q1: 网络爬虫是否合法?
A1: 网络爬虫的合法性主要取决于其操作是否符合相关法律法规以及网站的使用协议,合法的网络爬虫应当遵守网站的robots.txt文件规定,避免侵犯版权或进行不正当竞争。
Q2: 爬虫技术未来的发展趋势是什么?
A2: 预计未来网络爬虫将更加智能化,整合更多的人工智能和机器学习技术,以提高数据抓取的准确性和效率,隐私保护和数据安全将成为设计爬虫系统时更加关注的问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/868733.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复