


在互联网的海洋中,恶意爬虫就像是那些不请自来的海盗,它们悄无声息地侵入我们的网站,窃取信息,消耗资源,甚至影响正常的用户体验,面对这些网络空间的害虫,我们必须采取措施,保护我们的数字家园不受侵害,以下是一系列应对策略,旨在帮助我们识别、防御并反击这些恶意爬虫。


1. 检测与识别
要有效地对抗恶意爬虫,首先需要能够识别它们的活动,这通常涉及对日志文件的深入分析,以寻找异常模式。
识别指标:
访问频率:短时间内来自同一IP地址的大量请求。
访问模式:非人类的浏览路径,如直接访问深层链接。
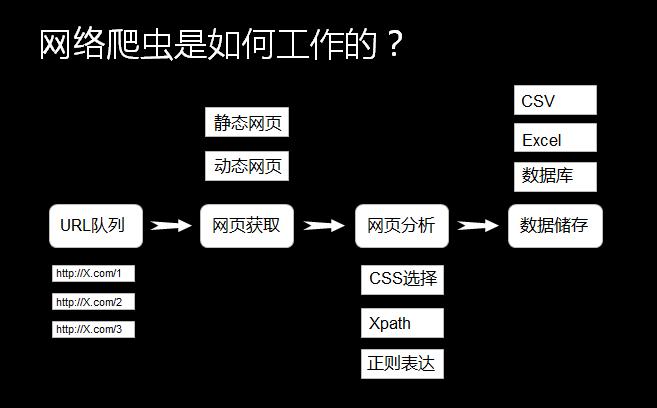
用户代理:伪装成合法浏览器的用户代理字符串,但常有细微差别。
2. 防御措施
一旦识别出恶意爬虫,下一步是部署防御机制来阻止它们的行为。
防御手段:
验证码:引入人机验证机制,区分正常用户与爬虫。

IP封锁:暂时或永久封锁表现出恶意行为的IP地址。
访问频率限制:对单个IP在一定时间内的访问次数进行限制。
蜜罐技术:设置陷阱URLs,吸引爬虫进入后进行识别和封锁。
3. 法律与政策
在某些情况下,可能需要借助法律手段来对付恶意爬虫。
法律途径:
服务条款:明确声明禁止未授权的数据抓取行为。
律师函:向爬虫操作者发送警告信或律师函。
法律诉讼:在严重的情况下,通过法律途径追究责任。
4. 持续监控与更新
对抗恶意爬虫是一个持续的过程,需要定期更新策略和工具。
监控工具:
日志分析软件:自动检测异常模式。
爬虫检测服务:使用第三方服务监测爬虫活动。
相关问题与解答
Q1: 如何平衡反爬虫措施对正常用户体验的影响?
A1: 可以通过以下方式平衡:
设计友好的验证码系统,确保不会对正常用户造成太大干扰。
对于访问频率限制,设定合理的阈值,避免误伤正常用户。
提供API供数据合法获取,减少对正常用户浏览体验的影响。
Q2: 如果对方无视IP封锁继续爬取怎么办?
A2: 可以采取以下措施:
联系对方的ISP,请求他们干预。
变换封锁策略,如动态更改被封锁的IP列表。
采用更复杂的防御机制,如行为分析、JavaScript挑战等。
作为最后手段,寻求法律帮助,通过法律途径解决问题。
面对网络恶意爬虫的威胁,我们需要采取一系列的措施来保护我们的网站安全,通过检测与识别、防御措施、法律与政策以及持续监控与更新,我们可以有效地减少恶意爬虫带来的风险,我们也需要注意平衡反爬虫措施对正常用户体验的影响,并在必要时寻求法律帮助来维护我们的权益。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/868690.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复