


在大数据时代,MapReduce作为一种广泛使用的编程模型,对于处理大规模数据集至关重要,它通过将计算任务划分为两个阶段——Map阶段和Reduce阶段,实现了对数据的高效处理,在作业运行过程中,了解和配置适当的日志级别,对于问题的追踪和性能优化来说极为重要,本文旨在深入探讨MapReduce的日志系统,包括不同日志级别的设置、日志收集模块的工作原理以及如何通过日志定位和解决问题。
MapReduce作业的日志可以分为两大类:Hadoop系统服务输出的日志和MapReduce程序输出的日志,MapReduce程序输出的日志又细分为作业运行日志和任务运行日志(Container日志),了解这些日志的分类和内容,有助于我们更有针对性地分析和处理问题。
让我们看看如何配置日志级别,在Hadoop 2.0中,可以通过修改mapredsite.xml配置文件来添加Map、Reduce和Application Master (AM)的日志级别,适当地调整这些级别,可以既方便问题的定位,也能有效减少日志输出量,从而降低存储和处理成本,特别是,在面对大量MapReduce作业的情况下,合理的日志级别设置显得尤为重要。
MapReduce的日志系统还具备自动压缩归档功能,默认情况下,当日志大小超过50MB时,系统会自动进行压缩,这种设计不仅节省了存储空间,而且通过压缩后的文件名规则,可以方便地管理和查询日志文件,最多保留最近的100个压缩文件的策略,也在另一方面保证了日志系统的高效运行。
通过以上分析可知,合理配置和使用MapReduce的日志级别对于作业的监控、问题定位及性能优化具有重大意义,我们将探讨一些常见问题及其解答,以期提供更具体的指导和帮助。
FAQs
Q1: MapReduce作业出现故障时,如何快速定位问题所在?
A1: 快速定位MapReduce作业问题的方法如下:
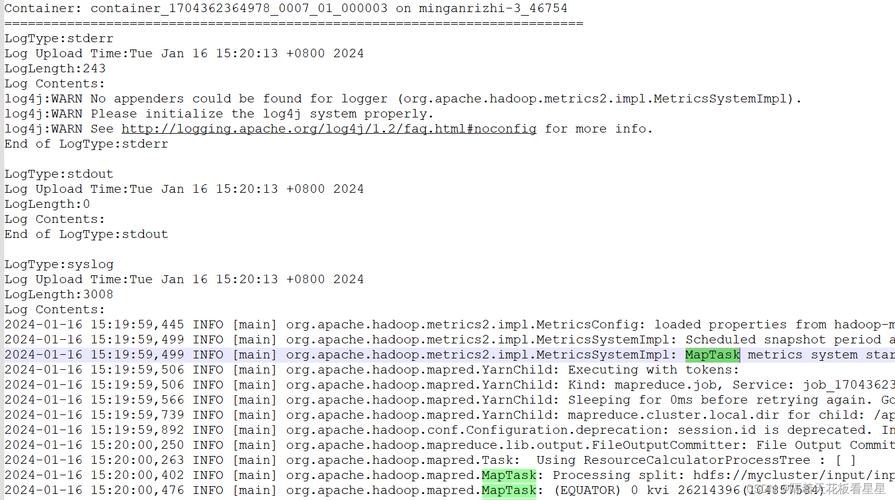
查看作业运行日志:首先应检查作业运行日志,这些日志包含了作业执行过程中的详细信息,能帮助您了解作业的整体运行状况。
分析任务运行日志:具体到每一个任务(Map或Reduce任务),其运行日志(Container日志)会提供更细节的错误信息或异常情况。
调整日志级别:如果默认的日志信息不足以定位问题,可以考虑临时提高日志级别,获取更详细的信息,可以将日志级别调整为DEBUG或TRACE级别。
利用监控工具:结合使用Hadoop集群的监控工具如Web UI、Ganglia或Ambari等,可以实时监控集群状态,辅助分析性能瓶颈和可能的故障点。
Q2: 如何平衡日志详细程度与存储成本之间的关系?
A2: 平衡日志详细程度与存储成本的方法如下:
合理设置日志级别:根据实际需要调整日志级别,既能满足问题定位的需求,又不产生过多的冗余信息。
利用自动压缩功能:启用并合理配置日志的自动压缩功能,可以在保证日志信息完整性的同时,有效控制日志文件的存储占用。
定期审查和清理日志:定期审查日志文件的保存情况,及时清理不再需要的日志文件,特别是对于那些已经压缩归档的旧日志文件。
分布式存储解决方案:考虑使用分布式存储解决方案来存储和管理日志文件,这样既可以提高存储效率,又能方便地进行扩展。
通过上述措施,即可实现日志管理的最优化,既保证了足够的信息用于问题定位和性能分析,又避免了不必要的存储成本。
通过深入理解MapReduce的日志系统及其配置方法,可以有效地提升作业的运行效率和可靠性,无论是面对故障诊断,还是日常的性能优化,合理的日志管理策略都是不可或缺的一环,希望本文提供的信息能够帮助您更好地掌握MapReduce作业的日志管理,进而优化您的大数据处理流程。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/868045.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复