


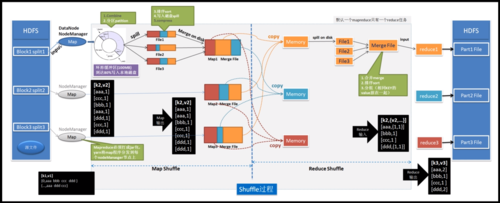
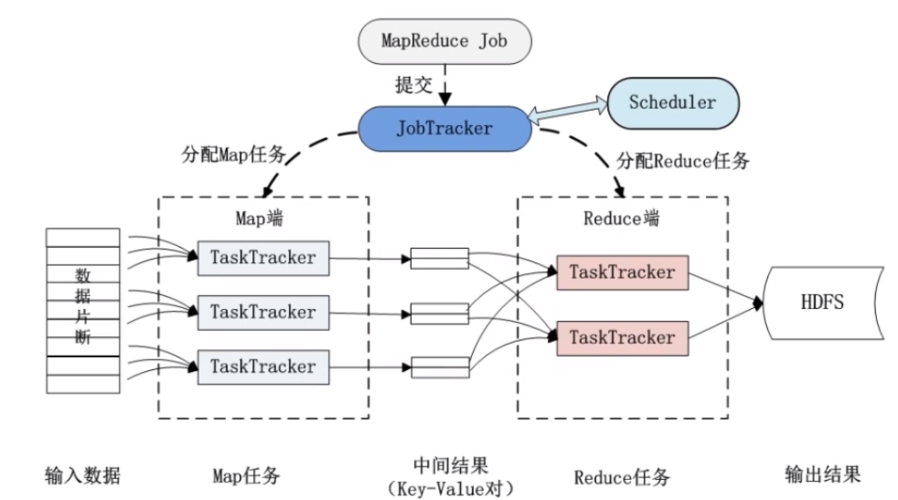
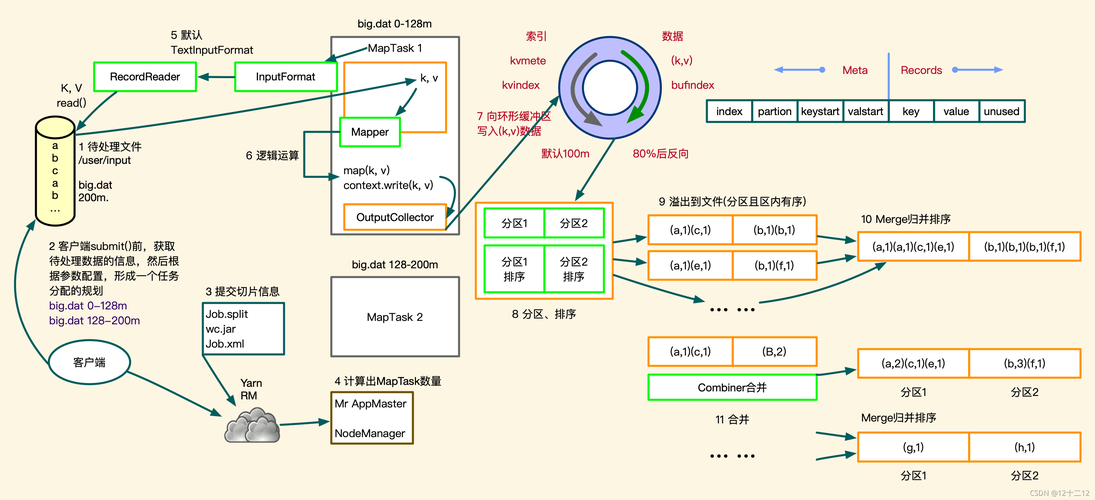
MapReduce是一个编程模型,用于处理和生成大数据集。在Map阶段,任务将输入数据分割成小块并分别处理;在Reduce阶段,结果被合并以得到最终输出。这种模式适用于各种计算环境,特别是大规模并行处理。
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要步骤组成:Map(映射)和Reduce(归约),下面是一个使用Python编写的简单MapReduce例子,用于计算文本中单词的出现次数。

(图片来源网络,侵删)
1、Mapper函数
def mapper(text):
words = text.split()
word_count = {}
for word in words:
if word in word_count:
word_count[word] += 1
else:
word_count[word] = 1
return word_count 2、Reducer函数
def reducer(mapped_data):
from collections import defaultdict
word_count = defaultdict(int)
for data in mapped_data:
for word, count in data.items():
word_count[word] += count
return dict(word_count) 3、MapReduce主函数
def mapreduce(inputs, mapper, reducer):
mapped_data = []
for input_data in inputs:
mapped_data.append(mapper(input_data))
result = reducer(mapped_data)
return result 4、示例输入和输出
假设我们有以下文本数据:
texts = [
"hello world",
"hello python",
"python is great",
"hello again"
] 我们可以使用以下代码调用MapReduce函数:
result = mapreduce(texts, mapper, reducer) print(result)
输出结果将是:
(图片来源网络,侵删)
{'hello': 3, 'world': 1, 'python': 2, 'is': 1, 'great': 1, 'again': 1} 这个例子展示了如何使用MapReduce模型处理文本数据,计算每个单词的出现次数,在实际应用中,MapReduce可以应用于更复杂的数据处理任务,如分布式排序、聚合等。
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/867982.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复