


MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要阶段组成:Map阶段和Reduce阶段,在MapReduce中,数据被分成多个独立的块,每个块在不同的节点上进行处理,这些处理结果被合并以产生最终的结果。
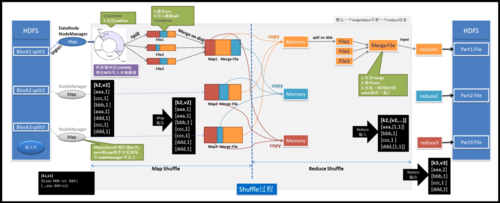

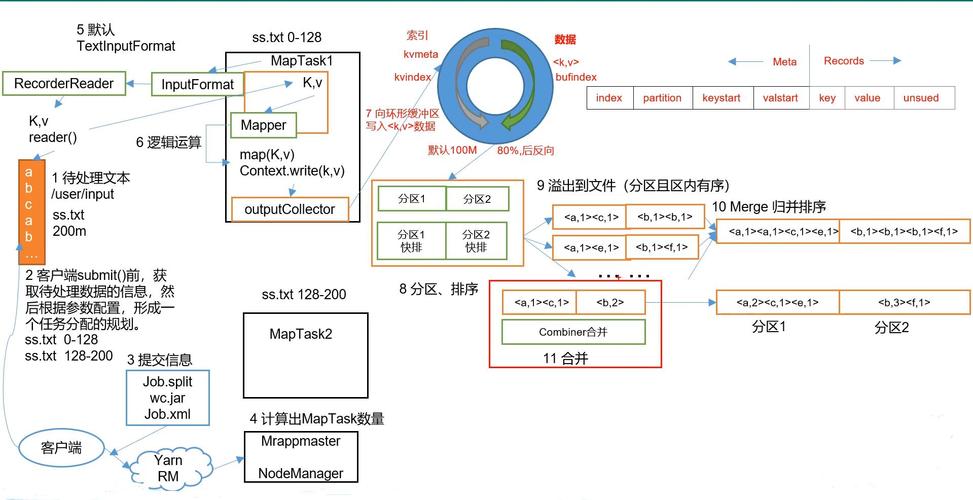
Map阶段:
输入数据被分割成多个独立的块(分片)。
每个分片独立地由一个Map任务处理。
Map任务将输入数据转换为一组键值对(keyvalue pairs)。
输出是中间键值对集合。
Reduce阶段:
所有具有相同键的键值对被分组在一起。
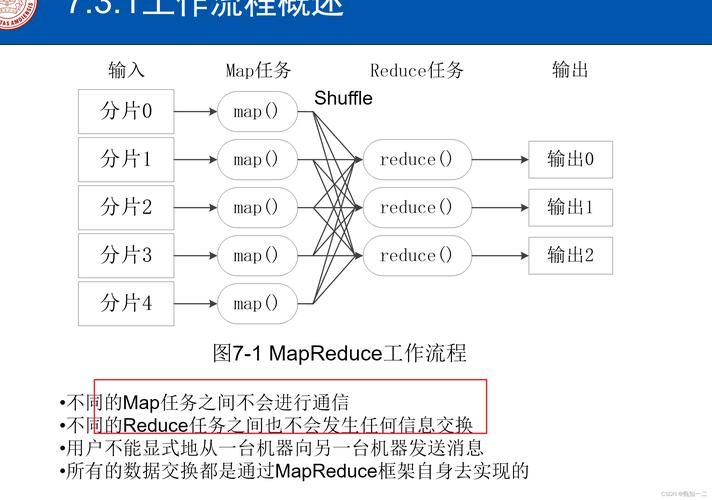
每个组的数据由一个Reduce任务处理。
Reduce任务对这些键值对进行聚合或组合操作,生成最终的结果。
MERGE INTO原理:
MERGE INTO是一种数据库操作,用于将两个表的数据合并到一起,它可以执行插入、更新和删除操作,以便将源表中的数据合并到目标表中。
以下是MERGE INTO的基本步骤:
1、匹配条件:确定源表和目标表中哪些行应该被合并,这通常通过比较两个表中的某个列来完成。
2、插入操作:对于源表中存在但目标表中不存在的行,将其插入到目标表中。
3、更新操作:对于源表和目标表中都存在的行,根据指定的条件更新目标表中的行。
4、删除操作:如果目标表中有某些行不在源表中,可以选择删除它们。
5、返回结果:返回合并操作的结果,通常是受影响的行数。
示例代码:
假设我们有两个表,一个是source_table,另一个是target_table,它们都有相同的结构,包括id和value列,我们希望将source_table中的数据合并到target_table中,如果id相同,则更新value;如果id不同,则插入新行。
MERGE INTO target_table AS T
USING source_table AS S
ON (T.id = S.id)
WHEN MATCHED THEN
UPDATE SET T.value = S.value
WHEN NOT MATCHED THEN
INSERT (id, value) VALUES (S.id, S.value); 在这个例子中,我们使用了SQL语言中的MERGE INTO语句来实现数据的合并,具体的语法和功能可能因不同的数据库系统而有所不同,但基本的原理和步骤是相似的。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/867603.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复