


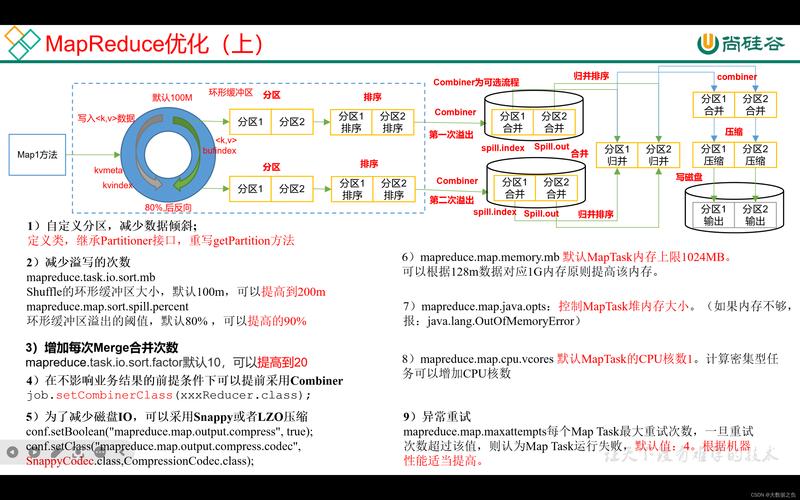
在大数据技术领域中,MapReduce是一种广泛使用的编程模型,用于大规模数据集的并行处理,它通过将计算任务分为映射和归约两个阶段,实现对数据的高效处理,MapReduce参数设置是优化作业性能的关键步骤之一,合理的参数配置可以显著提高作业执行效率并减少资源消耗,下面详细介绍MapReduce的关键参数设置:

1、内存和CPU资源配置
MapTask内存上限:mapreduce.map.memory.mb 参数用于设定一个Map Task可使用的内存资源上限,单位为MB,需根据具体任务的资源需求进行调整,默认值为1024MB。
ReduceTask内存上限:mapreduce.reduce.memory.mb 参数设定一个Reduce Task的内存资源上限,同样默认为1024MB,过大或过小的配置都可能导致任务失败或资源浪费。
CPU核数配置:mapreduce.map.cpu.vcores 参数设置每个Maptask可用的最多CPU core数目,合理配置可以提升任务处理速度,默认值为1。
2、Shuffle和Sort环节优化
Shuffle性能优化:Shuffle是MapReduce中数据从Mapper传输到Reducer的过程,优化该过程的参数可以大幅提高性能,调整mapreduce.shuffle.memory.buffer.percent可以改变Shuffle内存缓冲区的比例。
3、输入输出相关设置
InputSplit大小:输入文件按数据块分成多个InputSplit,其大小直接影响Mapper的数量和任务处理速度,根据实际情况调整mapreduce.input.fileinputformat.split.maxsize可以优化性能。
压缩输出:设置mapreduce.output.fileoutputformat.compress为true,可以启用MapReduce输出的压缩功能,节省存储空间并减少网络传输数据量。
4、通用调优策略
限制任务最大内存使用:通过调整mapred.task.maxvmem参数,可以限制任务的最大内存使用,避免因内存溢出导致的任务失败,但设置过低可能会影响任务执行效率。
合理设置JAR文件位置:通过mapreduce.job.jar参数指定包含MapReduce作业的JAR文件,确保所有必要的依赖能够被正确打包和分发。
除技术细节外,理解MapReduce的工作原理与各阶段的具体职责也极为重要,Mapper负责读取数据并产生键值对,而Reducer则处理这些键值对并输出最终结果,对于数据的Shuffle和排序过程,了解内部机制可以帮助进一步优化配置。
MapReduce的参数设置需要根据具体的应用场景和数据特性来调整,这涉及到内存和CPU资源的分配、Shuffle性能的优化、输入输出的设置等多个方面,只有通过合理的参数配置,才能确保MapReduce作业的高效稳定运行,对于初学者而言,建议从默认参数开始,逐步调整并测试不同配置的效果,以积累经验,对于已有经验的开发者,定期回顾和调整参数配置,结合最新的Hadoop版本和硬件环境进行优化,是提升性能的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/867572.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复