


MapReduce Setup获取文件名:获取训练作业日志的文件名


在MapReduce编程模型中,训练作业日志是至关重要的组成部分,它记录了整个MapReduce作业的执行过程,包括任务分配、执行状态、错误信息等,了解如何获取这些日志文件名对于调试和优化作业性能具有重要意义,本文将详细介绍如何在MapReduce设置过程中获取这些日志文件名。
MapReduce日志系统
MapReduce框架通常由一个主节点(JobTracker)和多个从节点(TaskTracker)组成,每个节点都会生成日志文件,记录其操作和状态,在Hadoop等实现中,这些日志默认存储在本地文件系统中,但也可以通过配置输出到其他位置。
获取日志文件名的方法
1. 查看配置文件
Hadoop配置文件: Hadoop集群的配置文件(如hadoopenv.sh或coresite.xml)可能包含日志目录的位置,查找这些文件中的hadoop.log.dir属性,它可以告诉你日志文件存放的目录。
2. 使用命令行工具
Hadoop Web界面: 如果启用了Hadoop的Web界面,可以通过访问JobTracker的Web界面来查看作业详情,其中包含了日志文件的链接。
Hadoop fs ls命令: 使用Hadoop文件系统命令hadoop fs ls /tmp可以列出临时目录下的所有文件,包括日志文件。
Yarn REST API: 如果使用的是YARN(Yet Another Resource Negotiator),可以通过YARN的REST API来检索作业的日志文件路径。
3. 编程方式获取
编写MapReduce程序: 可以在MapReduce程序中添加代码,使其在运行时将日志文件名写入特定位置或发送到外部系统。
使用Flume或其他日志收集工具: 配置Flume等日志收集系统,实时地从节点收集并传输日志数据到中央存储或分析系统。
日志管理和最佳实践
集中管理: 使用如Elasticsearch或Apache Flume等工具集中管理日志,便于搜索和分析。
定期清理: 定期清理旧的日志文件,避免占用过多磁盘空间。
监控和报警: 设置监控系统监控日志文件的大小和数量,异常时及时报警。
相关问答FAQs
Q1: 如何通过编程获取当前运行的MapReduce作业的日志文件名?
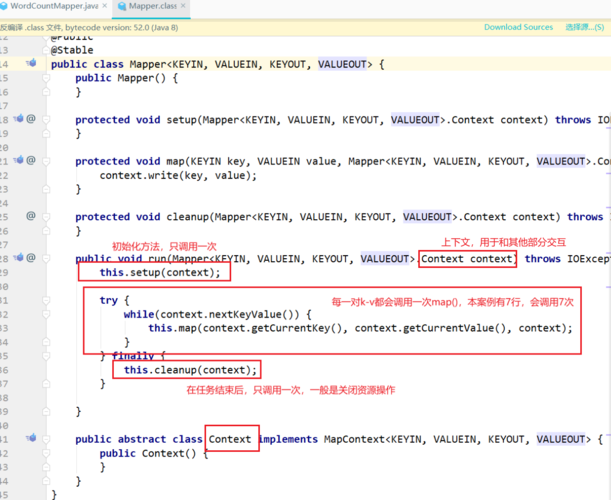
A1: 你可以在MapReduce作业中添加自定义的日志处理代码,在Mapper或Reducer的cleanup方法中,你可以获取作业的配置信息,并将日志文件名写入HDFS或其他存储系统中,这需要你有权限修改和编译MapReduce作业的源代码。
Q2: Hadoop集群中的日志文件通常存放在哪里?
A2: 在Hadoop中,日志文件默认存放在各个节点的本地文件系统的/tmp目录下,具体的路径可能会因Hadoop版本和配置不同而有所差异,但通常可以通过查看hadoop.log.dir配置项来确定确切位置,日志也可以被配置为存储在其他位置,如HDFS。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/867314.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复