


MapReduce是一种编程模型,用于处理和生成大数据集。在Hadoop中,”files_CLEAN FILES”可能指的是经过MapReduce作业处理后的输出文件,它们通常存储在HDFS(Hadoop分布式文件系统)上,并且是清洗过的数据文件,可供进一步分析或使用。
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对(keyvalue pair),在Reduce阶段,所有具有相同键的值被组合在一起,并应用一个归约函数以生成最终结果。


(图片来源网络,侵删)
以下是一个简单的MapReduce程序示例,用于清理文件名中的空格和其他不需要的字符:
from mrjob.job import MRJob
import re
class FilesCleaner(MRJob):
def mapper(self, _, line):
# 提取文件名
file_name = line.strip()
# 清理文件名,移除空格和非字母数字字符
cleaned_file_name = re.sub(r'W+', '', file_name)
# 输出清理后的文件名及其长度
yield cleaned_file_name, len(cleaned_file_name)
def reducer(self, key, values):
# 计算每个清理后的文件名的平均长度
total_length = sum(values)
count = len(values)
average_length = total_length / count
yield key, average_length
if __name__ == '__main__':
FilesCleaner.run() 在这个示例中,我们首先导入了mrjob库,它是一个用于编写和运行MapReduce作业的Python库,我们定义了一个名为FilesCleaner的类,该类继承自MRJob。
在mapper方法中,我们从输入行中提取文件名,并使用正则表达式清理文件名,移除其中的空格和非字母数字字符,我们将清理后的文件名作为键,文件名的长度作为值输出。
在reducer方法中,我们接收到相同键的所有值(即所有清理后的文件名的长度),并计算它们的总和和数量,我们计算平均长度并将其作为结果输出。
我们在脚本的主入口处调用FilesCleaner.run()来运行MapReduce作业。
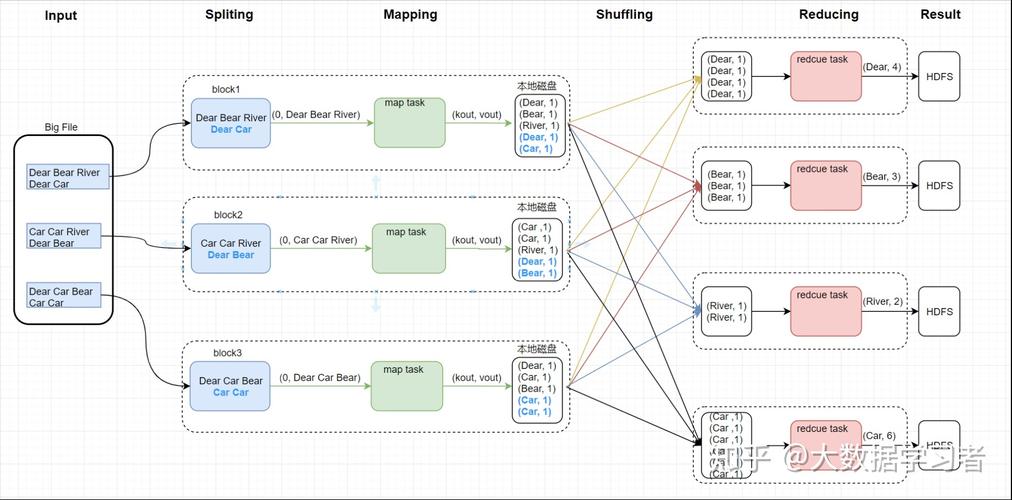
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/867198.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复