


MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块(分片),然后每个分片都独立地进行处理,我们将详细讨论Map阶段的分片过程。
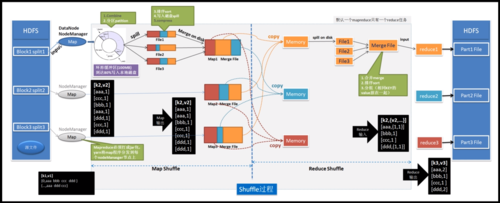

1. Map阶段的分片过程
在Map阶段,输入数据会被分成多个分片,每个分片都会被分配给一个Map任务进行处理,这个过程通常由一个称为InputFormat的组件负责。InputFormat会根据输入数据的存储方式(例如HDFS、本地文件系统等)将数据划分为多个分片,并为每个分片创建一个键值对(keyvalue pair)。
1.1 分片策略
分片策略决定了如何将输入数据划分为多个分片,常见的分片策略有:
基于行数的分片:按照文件中的行数进行划分,每个分片包含固定数量的行。
基于字节大小的分片:按照文件的大小进行划分,每个分片包含固定大小的字节。
基于记录边界的分片:根据记录的边界进行划分,确保每个分片中的记录完整。
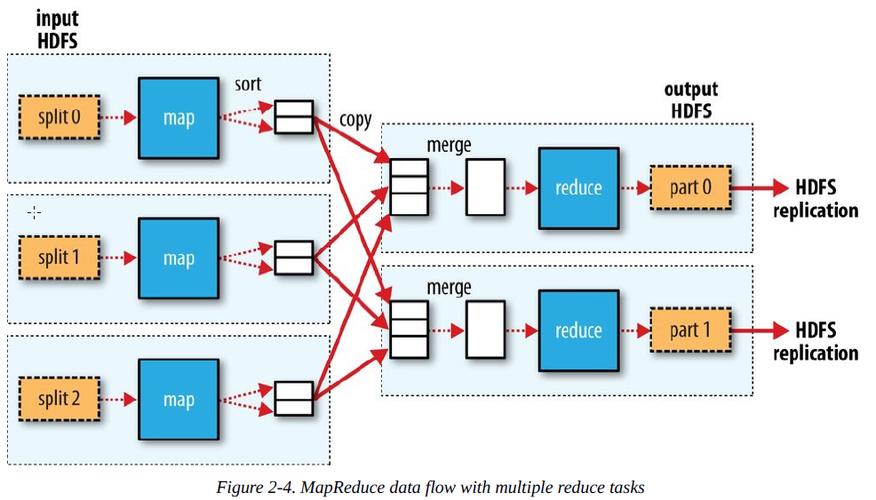
1.2 分片大小
分片的大小对于MapReduce的性能至关重要,过大的分片可能导致某些节点负载过重,而过小的分片可能导致过多的网络传输开销,选择合适的分片大小是优化MapReduce性能的关键。
1.3 示例代码
以下是一个使用Hadoop MapReduce API的Java代码示例,展示了如何自定义分片策略:
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.mapreduce.lib.input.LineRecordReader; public class CustomShardingExample { public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "Custom Sharding Example"); job.setJarByClass(CustomShardingExample.class); job.setMapperClass(MyMapper.class); job.setReducerClass(MyReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); // 设置自定义的分片策略 FileInputFormat.addInputPath(job, new Path(args[0])); FileOutputFormat.setOutputPath(job, new Path(args[1])); job.setInputFormatClass(MyCustomInputFormat.class); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
在这个示例中,我们通过设置job.setInputFormatClass(MyCustomInputFormat.class)来指定自定义的分片策略。MyCustomInputFormat类需要继承自FileInputFormat并覆盖相应的方法来实现自定义的分片逻辑。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/866254.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复