


MapReduce与Hadoop SQL on Hadoop
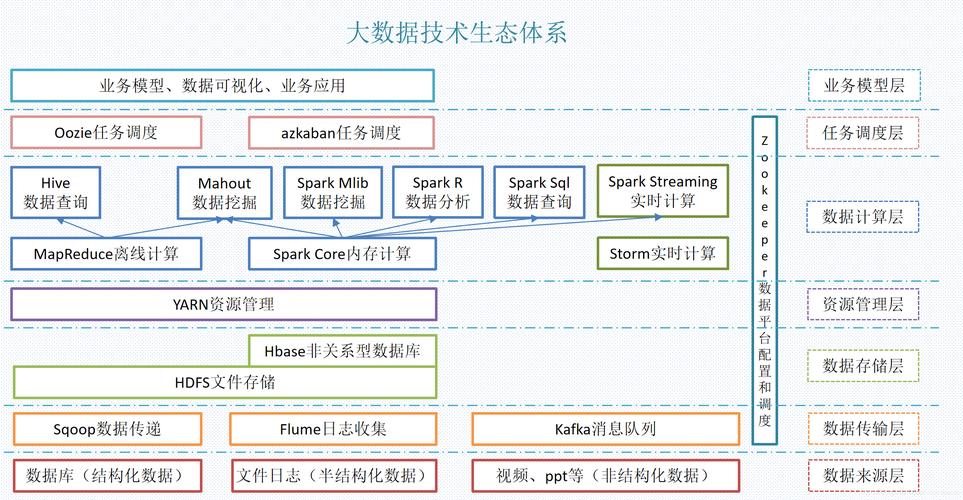

MapReduce是处理大规模数据集的一种编程模型,而Hadoop是一个开源框架,它用Java编写,基于MapReduce来处理大型数据集,Hadoop SQL on Hadoop 则是在Hadoop环境下使用SQL查询语言进行数据处理的技术。
MapReduce基础
MapReduce模型主要由两个阶段组成:Map阶段和Reduce阶段,在Map阶段,系统将输入数据拆分成独立的数据块,之后交给多个Map任务进行处理,每个Map任务会生成一组中间键值对,随后,通过框架的排序和混洗(Shuffle)过程,具有相同键的值被发送给相应的Reduce任务,在Reduce阶段,每个Reduce任务处理接收到的数据并生成最终的结果。
MapReduce的设计思想在于分而治之,通过分布式计算提高处理大规模数据的效率,其优点在于可扩展性和容错性,但缺点包括编程复杂度高,对实时处理支持不足。
Hadoop的核心架构由两部分组成:HDFS(Hadoop Distributed File System)和MapReduce,HDFS是一个分布式文件系统,它能够在多台机器上存储大量数据,而MapReduce则作为计算引擎在这些数据上运行作业。
Hive和SQL on Hadoop
Apache Hive是构建在Hadoop之上的数据仓库软件,它允许用户使用类似SQL的语言(称为HQL)来查询存储在HDFS中的数据,Hive将SQL查询转换成MapReduce作业来处理数据。
Hive不仅支持结构化数据查询,还可以处理半结构化及非结构化数据,这使得数据分析人员可以使用熟悉的SQL语言在大数据集上执行复杂的分析操作,极大地降低了学习曲线。
与传统数据库的互操作性也是Hadoop生态的一个重要方面,工具如Sqoop能够高效地在关系型数据库和Hadoop之间传输数据,使得传统数据库可以与Hadoop协同工作,实现数据的互补和增值。
通过使用SQL on Hadoop技术,企业能够将传统的数据仓库延伸到Hadoop平台上,实现更广泛的数据治理和分析能力,这种技术的应用不仅限于数据查询,还包括数据挖掘、报告生成和ETL(Extract, Transform, Load)处理等。
安装和配置
安装Hadoop前需确保系统中已安装Java,可以通过java version命令检查Java是否已安装,若无,则需先下载和安装Java Development Kit(JDK),下载Hadoop的最新版本后解压到本地文件系统中,便可开始配置和使用。
Hadoop可以在Linux、Windows、Mac OS X等多种操作系统上运行,其强大的跨平台特性使其成为企业和开发者优选的大数据处理平台。
MapReduce与Hadoop SQL on Hadoop的结合为大数据的处理和分析提供了强大的技术支持,通过利用Hive等工具,用户可以用熟悉的SQL语言操作大数据,极大地提高了开发效率和数据处理能力,对于希望深入了解和应用大数据技术的人来说,了解这些技术的原理和实践将是一个重要的起点。
相关问答FAQs
什么是MapReduce?
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它包括两个阶段:Map阶段和Reduce阶段,在Map阶段,系统将输入数据拆分成独立的数据块,之后交给多个Map任务进行处理,每个Map任务会生成一组中间键值对,随后,通过框架的排序和混洗(Shuffle)过程,具有相同键的值被发送给相应的Reduce任务,在Reduce阶段,每个Reduce任务处理接收到的数据并生成最终的结果。
如何在Hadoop上实现SQL查询?
在Hadoop上实现SQL查询主要通过使用Apache Hive这一数据仓库软件,Hive接受SQL查询(称为HQL),并将其转换为MapReduce作业来执行,用户可以像操作传统SQL数据库那样操作存储在HDFS中的大型数据集,还有其他工具如Impala和Spark SQL也能在Hadoop上实现SQL查询,它们提供了不同于MapReduce的执行引擎,以提升查询性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/866203.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复