


MapReduce是一种编程模型,用于大规模数据处理,它主要包括两个阶段:Map阶段和Reduce阶段,在Map阶段,数据被分成小块,由不同的节点并行处理;而在Reduce阶段,各个节点处理的结果将被整合汇总,下面将详细探讨在开发MapReduce应用时应遵循的规则:
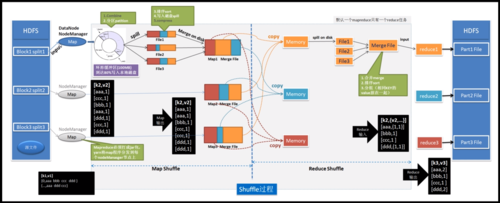

1、MapReduce程序的基本结构
Mapper类继承与实现:开发MapReduce应用时,需要创建一个Mapper类,这个类继承自Hadoop框架中的Mapper类,在Mapper类中,需要重写map方法,该方法接收输入数据并产生一组中间keyvalue对。
Reducer类继承与实现:类似地,需要创建一个Reducer类,继承自Hadoop框架中的Reducer类,在Reducer类中实现reduce方法,该方法以Mapper的输出作为输入,对具有相同key的值进行合并处理。
2、MapReduce开发中的高级设置
使用setup方法:在Reducer类中,除了reduce方法外,还可以实现setup方法,setup方法在reduce方法调用前执行,可用于初始化操作,如建立数据库连接或加载必要的配置信息。
使用Context对象:MapReduce任务中使用Context对象来管理应用级别的数据,在Reducer中,通过Context对象调用write方法将最终结果写出。
3、数据处理规则
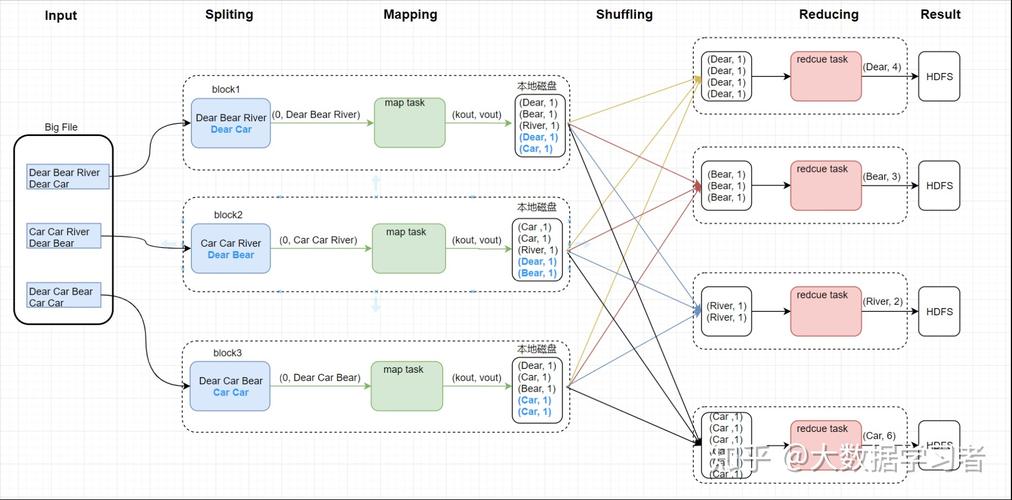
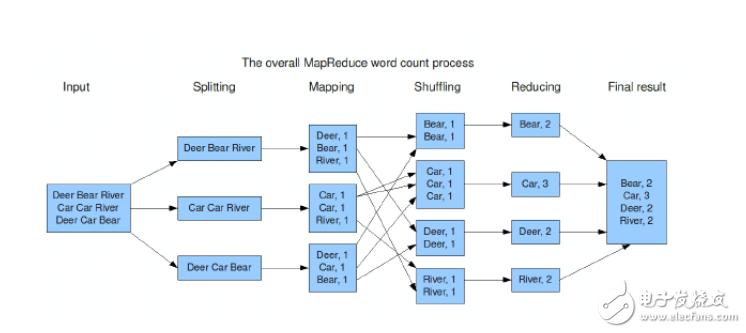
输入数据格式处理:Map阶段的输入数据通常是键值对的形式,开发者需确保正确解析这些键值对,以便它们可以被map方法正确处理。
输出数据格式处理:在Reduce阶段,输入为不同Mapper输出的具有相同key的键值对集合,开发者需要在reduce方法中汇总这些值,并输出最终结果。
4、优化技术和性能考量
合理设计key的选择与分片:选择合适的key及其分片策略对于优化MapReduce作业至关重要,合理的分片可以确保工作负载均匀分配到各个节点上。
考虑数据处理的内存与I/O效率:在处理大数据量时,应尽量减少I/O操作和内存使用,避免在map或reduce方法中存储大量数据到内存中。
直接查找相关“mapreduce setup park”的具体开发规则时,可能发现信息比较有限,但基于MapReduce的通用开发知识和技术原则,上述内容应能提供相对全面的指导,将以上核心信息表格化,便于快速参考:
| 组件 | 核心方法 | 功能描述 |
| Mapper | map | 处理输入数据,产生中间keyvalue对 |
| Reducer | reduce | 对中间数据按key汇总,输出最终结果 |
| setup | 初始化操作,如建立配置或连接 | |
| Context | write | 用于写出处理结果 |
MapReduce应用的开发涉及对Mapper和Reducer类的扩展及配置,正确的数据处理和优化策略是保证应用效率的关键,使用如setup这样的高级功能可以进一步改善应用的性能和可用性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/866144.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复