


在探讨MapReduce中的map输出合并问题时,需要理解其核心目的是通过有效地数据处理来优化性能和资源使用,Map阶段的输出经常是大量且分散的,而合并这些输出可以显著减少数据处理的复杂性和网络传输的需求,下面将详细分析MapReduce中map输出合并的各种策略和实现方式:
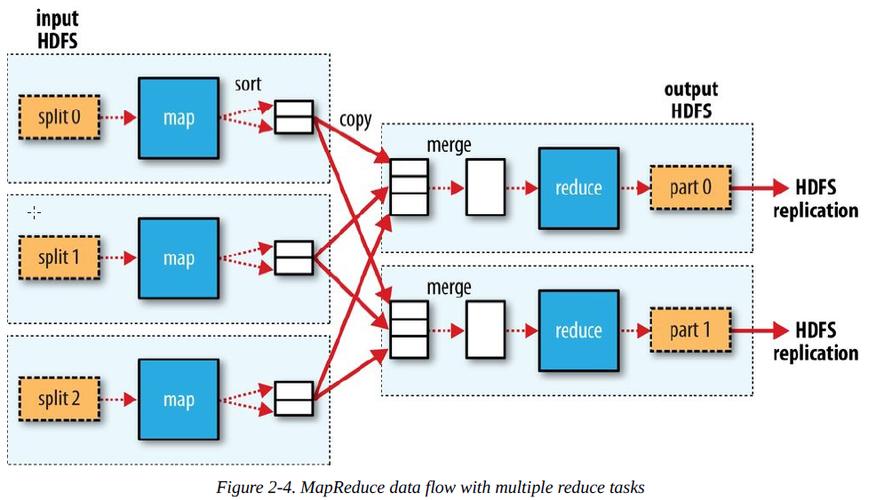

1、Map端的输出合并
使用Combiner: 在Map阶段完成后,每个Map任务会生成大量的中间数据,Combiner是一种优化手段,它类似于一个本地的Reducer,但它在Map端执行,Combiner的作用是在数据传输前对Map输出进行局部聚合,以减少数据量,这样不仅减少了数据传输的负担,也减轻了Reduce阶段的压力。
优化内存和磁盘操作: Map端的输出通常存储在内存缓冲区中,当内存缓冲区满时,数据会被溢写到磁盘上,这一过程中,如果设置了Combiner,它会对溢出的数据进行合并操作,从而减少最终存储在磁盘上的数据量,这种合并操作可以有效减少后续处理的数据规模和复杂度。
2、Reduce端的数据整合
关联条件的运用: 在处理大数据的连接(Join)操作时,MapReduce框架提供了一种优化方法,即通过将关联条件作为Map输出的键(Key),这样可以确保所有需要被连接的数据项都被发送到同一个Reduce任务,在Reduce阶段,来自不同Map任务但具有相同键的数据将被整合,从而实现数据的串联和合并。
资源分配和调优: Reduce端的处理能力可以通过调整内存缓冲区的大小进行优化,通过参数mapred.job.shuffle.input.buffer.percent来配置,可以提高Reduce任务处理大量数据时的性能,合适的资源分配能更好地管理内存和磁盘资源,提高数据处理效率。
3、Map阶段的数据处理
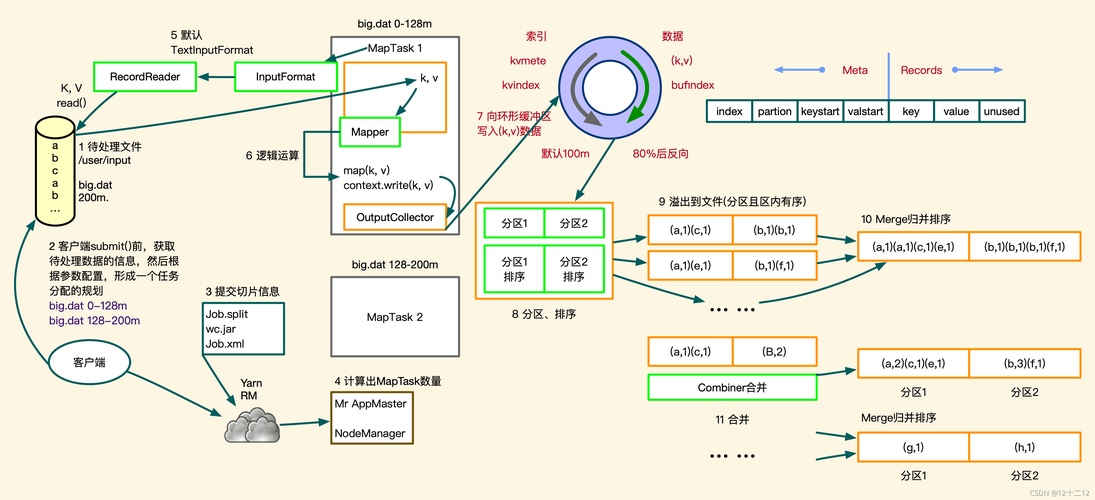
Map阶段的Join操作: 在某些情况下,可以在Map阶段完成全部的Join操作,而不依赖于Reduce阶段,这种方法利用了Mapper阶段的计算资源,避免了数据在Map和Reduce任务之间的大量数据传输,通过适当的设计和配置,可以显著提升数据处理的效率并缩短响应时间。
MapReduce中Map输出的合并是一个关键环节,涉及到数据处理的效率和资源使用最优化,通过使用Combiner、优化内存和磁盘操作、以及智能地使用关联条件和资源调优,可以大幅度提升数据处理的速度和减少资源的消耗,在实施这些策略时,考虑数据的特性和实际应用场景是非常关键的,这将进一步帮助优化MapReduce作业的总体性能。
FAQs
Q1: 如何在MapReduce中设置Combiner?
A1: 在MapReduce中设置Combiner通常很简单,你可以在编写MapReduce程序时,指定Combiner类,或者直接使用Reduce类作为Combiner,大多数MapReduce框架允许你在作业配置中明确设置Combiner,在Hadoop中,你可以这样做:
job.setCombinerClass(Reduce.class);
这将使得Map输出在传输到Reduce之前被Combiner处理,以减少数据量。
Q2: 为何在MapReduce中使用Combiner能提高性能?
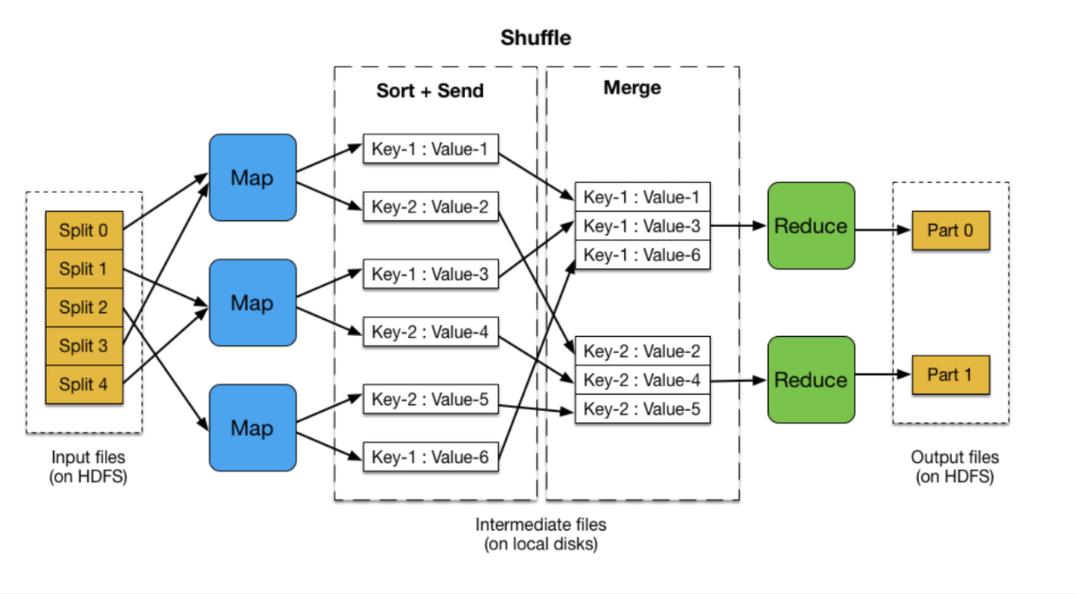
A2: 使用Combiner能显著提高MapReduce性能,因为它减少了Map和Reduce之间需要传输的数据量,在很多数据处理场景中,Map任务会产生大量冗余或相似的数据,Combiner通过在数据离开Map节点前进行局部聚合,减少了数据的冗余性,从而减少了网络上的数据传输量和Reduce阶段的输入负载,这不仅能加快数据处理速度,也能节约网络带宽和存储资源的使用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/865940.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复