


在大数据时代,MapReduce作为一种数据处理模型,对于数据的处理和分析起到了至关重要的作用,了解如何查看和分析MapReduce的日志,对于优化数据处理流程、调试程序错误具有重要意义,本文将深入探讨如何查看MapReduce日志,包括日志的位置、如何启用历史服务器以及日志的种类等方面,帮助读者更好地理解和应用MapReduce日志分析。

MapReduce日志基础
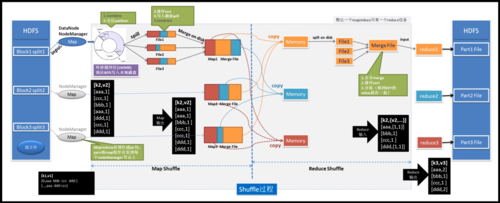
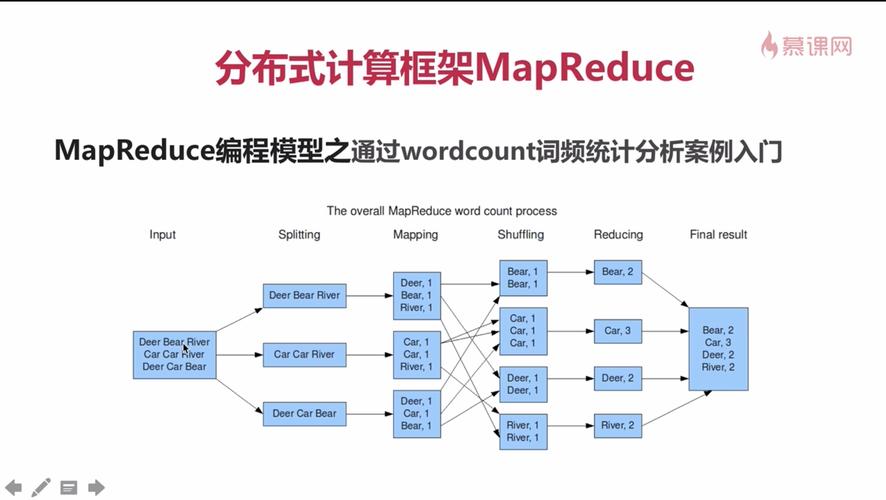
MapReduce作业的执行涉及大量的日志信息,这些信息记录了作业的执行情况,包括作业的开始时间、结束时间、所消耗的资源、各个阶段的错误等信息,Hadoop系统中的MapReduce日志主要分为两大类:系统服务输出的日志和MapReduce程序输出的日志,系统服务输出的日志主要包括了Hadoop系统运行时的服务日志,如NameNode、DataNode等;而MapReduce程序输出的日志则是用户提交的MapReduce作业在运行过程中产生的日志。
日志位置与查看方法
1. MapReduce任务查看页面
日志访问路径:在Hive客户端执行HQL查询报错时,需要通过MapReduce日志来定位问题,日志文件通常存放在Hadoop的文件系统中,具体可以通过Hadoop的用户界面访问,或者直接在文件系统的相应目录下查找。
历史服务器角色:为了查看MapReduce日志,需要启动HistoryServer,HistoryServer是Hadoop的一个服务,用于保存和提供MapReduce作业的历史日志信息,默认情况下,HistoryServer可能未启动,需要手动启动以查看日志信息。
2. 日志种类和存放路径
作业运行日志:这类日志包含了作业的整体信息,如作业的配置信息、启动时间等,通常存放在Hadoop文件系统特定的目录下,如/user/hadoop/job_history/。
任务运行日志(Container日志):每个MapReduce任务都会生成多个容器(Container),每个容器的日志详细记录了该容器内任务的执行情况,这些日志同样存放在Hadoop文件系统的特定目录下。
日志分析与应用
1. 日志分析的重要性
性能优化:通过分析日志中的时间戳信息和资源使用情况,可以发现作业执行的瓶颈,进行相应的优化调整。
错误调试:当作业执行失败或出现异常时,通过查看日志中的错误信息,可以快速定位问题所在,减少调试时间。
2. 日志分析的技巧
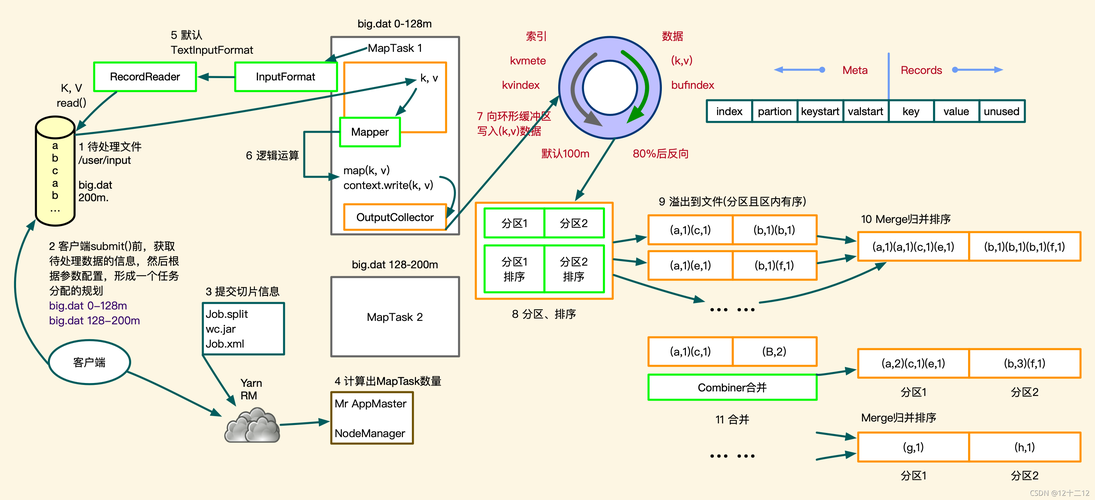
关注关键信息:在日志中,应重点关注作业的启动和结束时间、错误或异常信息、计数器信息等。
利用工具辅助:可以使用文本查看和搜索工具(如grep、awk等),或专业的日志分析工具来辅助分析日志信息,提高分析效率。
常见问题解答
Q1: 如何启动HistoryServer?
启动步骤:进入hadoop的bin目录下,执行sbin/starthistoryserver.sh命令,启动后,可以通过jps命令确认HistoryServer是否已启动。
Q2: MapReduce日志中包含哪些重要信息?
重要信息:包括作业的启动和结束时间、所使用的资源、每个阶段的耗时、错误或异常信息、输入输出数据统计等。
通过上述分析,我们可以看到,MapReduce日志不仅对于问题的发现和解决至关重要,同时也是优化作业性能、提升系统稳定性的重要手段,掌握如何查看和分析MapReduce日志,对于每一个从事大数据处理工作的人来说,都是一项必备的技能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/865875.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复