


在大数据时代,Apache Spark作为一个高效的大数据处理工具,常用于处理海量数据集的运算工作,而MySQL作为一种广泛使用的关系型数据库管理系统,其数据的安全性与完整性使其成为存储管理重要数据的首选,当需要结合Spark进行数据处理并将结果存储至或从MySQL数据库中读取数据时,如何有效地实现这一过程变得尤为重要,本文将探讨Spark作业访问MySQL数据库的不同方案,旨在为开发者提供全面而准确的指导。
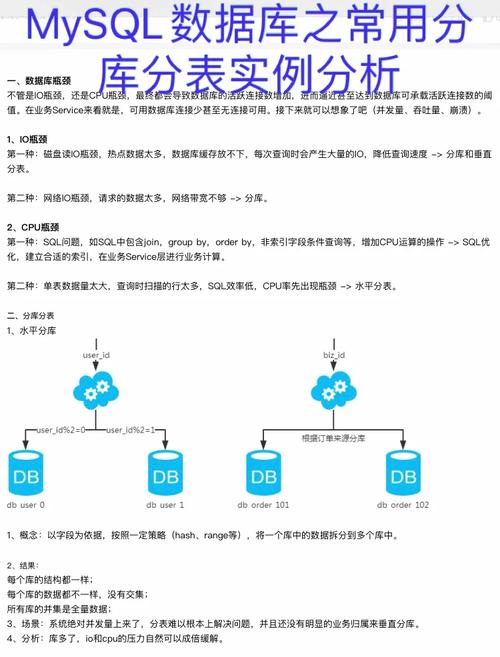

使用JDBC连接
1. 核心步骤:
驱动加载:确保有对应版本的JDBC驱动jar包,以便Spark作业能通过它连接到MySQL数据库。
建立连接:通过SparkSession或SparkContext对象,使用JDBC连接参数(URL、用户名、密码等)来建立到MySQL数据库的连接。
执行操作:利用Spark SQL的功能,通过JDBC连接执行对MySQL数据库的读写操作,包括数据的插入、查询等。
2. 特点与优势:
通用性强:几乎所有支持JDBC的数据库都可以用此方法连接,兼容性好。
集成度高:可以直接在Spark SQL中操作,对于熟悉SQL的用户来说较为方便。
使用PyMySQL连接
1. 核心步骤:
安装库:在Python环境中安装PyMySQL库,这是Python用于连接MySQL数据库的一个库。
创建连接:通过编写Python代码,使用PyMySQL提供的API创建到MySQL数据库的连接。
执行操作:通过编写Python代码,利用PyMySQL执行对MySQL数据库的读写操作。
2. 特点与优势:
Python友好:对于使用Python编写Spark作业的用户,可以通过熟悉的Python代码直接操作数据库。
灵活性高:相较于直接使用JDBC,使用Python代码可以更加灵活地控制数据库操作逻辑。
使用云原生数据仓库AnalyticDB MySQL版
1. 核心步骤:
数据仓库选择:选择云原生数据仓库服务,如阿里云的AnalyticDB MySQL版。
创建连接:根据云服务提供商的文档,设置并创建到自建MySQL数据库或云数据库RDS MySQL、云原生数据库的连接。
提交作业:通过云服务提供的界面或API提交Spark SQL作业,访问上述数据库。
2. 特点与优势:
云服务集成:充分利用云服务的便利性,简化了大数据处理与数据库操作的流程。
易于扩展:云服务通常提供易于扩展的资源,可根据需求动态调整计算资源和存储资源。
使用DLI Spark作业
1. 核心步骤:
创建队列:在DLI(数据湖搜索索引)中创建队列,选择合适的计费模式。
创建增强型跨源连接:配置增强型跨源连接,以便安全高效地访问MySQL数据库。
提交作业:通过DLI提交Spark作业,实现对MySQL数据库的读写操作。
2. 特点与优势:
安全性高:增强型跨源连接提供了更高的安全性保障。
性能优化:专为AWS环境优化,提高了在AWS云环境中访问MySQL数据库的性能。
分析或建议
在选择Spark作业访问MySQL数据库的方案时,应考虑以下因素:
开发语言偏好:基于Java/Scala还是Python,选择JDBC或PyMySQL。
部署环境:在云端还是本地,是否需要考虑云服务的集成。
性能需求:不同方案在性能上有所差异,选择最佳性能的解决方案。
安全要求:数据传输和访问的安全级别也是选择方案的重要考量点。
为确保成功实施以上方案,还需注意以下几点:
确保所有依赖和驱动程序都已正确安装和配置。
测试连接和作业执行,以确保兼容性和性能满足需求。
考虑异常处理和错误回滚策略,保证数据一致性和作业的稳定性。
Spark作业访问MySQL数据库有多种方案可供选择,每种方案都有其独特的优势和适用场景,开发者应根据项目的具体需求,综合考虑各种因素,选择最合适的方案来实现Spark作业与MySQL数据库的有效连接和高效通信。
相关问答FAQs
Q1: 使用JDBC连接MySQL时,如何保证连接的安全性?
A1: 确保使用SSL连接,并对敏感信息如用户名和密码进行加密处理,避免在代码或配置文件中明文存储,限制数据库权限,仅授予Spark作业所需的最小权限。
Q2: 如果遇到性能瓶颈,有哪些优化建议?
A2: 可以尝试增加Spark作业的资源分配,如增加executor的内存和CPU数量;优化SQL查询语句,避免全表扫描;考虑使用缓存机制减少数据库的访问次数;合理分区和并行化处理也能显著提升性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/865150.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复