


在大数据领域,Hadoop和MapReduce是两个核心概念,Hadoop作为一个分布式计算平台,而MapReduce则是其执行计算任务的编程模型,它们之间的关系紧密且互补,共同构成了大规模数据处理的基础架构,下面将分析Hadoop与MapReduce之间的关系以及MapReduce与其他组件的关系:


关于Hadoop与MapReduce的关系:
1、组成与作用:
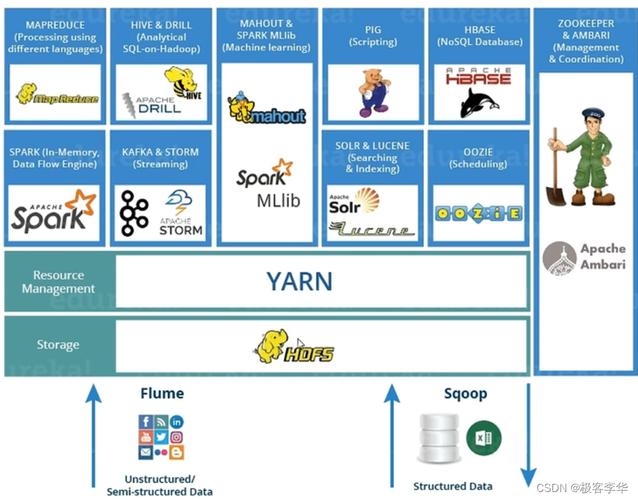
Hadoop是由多个组件构成的生态系统,包括Hadoop Distributed File System(HDFS)、MapReduce、Hive、Zookeeper、HBase等,HDFS和MapReduce是其最基础也是最重要的组成部分。
MapReduce是Hadoop中的计算框架,专门负责执行数据处理任务,它通过Map(映射)和Reduce(归约)两个阶段来处理大量数据,并将结果存储在HDFS中。
HDFS则作为存储层,提供高容错和高吞吐量的数据存储服务,适合部署在多种廉价硬件上,这种设计确保了数据的并行处理能力,以及整个Hadoop系统的伸缩性和容错性。
MapReduce的有效执行依赖于HDFS的稳定和高效数据存储,HDFS的数据块分布策略直接影响MapReduce任务的执行效率和数据本地化计算的优势。
HDFS和MapReduce的协同工作实现了数据处理和存储的高效配合,使得整个系统能够支持海量数据的快速处理和分析。
2、设计理念与实现:
Hadoop的设计主要是为了解决处理海量数据的问题,通过分布式计算和存储资源,提高处理效率和系统的容错能力。
MapReduce允许开发者通过编写简单的Map和Reduce函数来实现复杂的分布式计算,隐藏了大部分并行化和分布式处理的复杂性。
MapReduce的运行机制是通过将问题分解为更小的任务,分布在多个节点上并行处理,之后将结果汇总,这个过程完全依赖于HDFS的文件系统支持。
尽管MapReduce在企业中的应用逐渐减少,但它的出现极大促进了早期大数据离线计算的发展,解决了编程难度大、不易扩展等问题。
随着技术的发展,虽然MapReduce可能不再适用于实时计算或流式计算等场景,但它在批量处理大规模数据集方面仍显示出巨大潜力。
MapReduce与其他组件的关系:

1、功能分工与整合:
MapReduce作为核心计算框架,提供了业务逻辑的编码模板,而HDFS负责数据的分布式存储,这种分工使得每个组件可以专注于其核心功能,同时保证了整体系统的效率和稳定性。
YARN(Yet Another Resource Negotiator)是Hadoop中负责资源管理的平台,它优化了MapReduce任务的资源分配和调度,进一步提高了计算框架的效能和灵活性。
其他组件如Hive、Pig等建立在MapReduce之上,提供更高级的查询语言和数据处理功能,扩展了Hadoop的应用场景和用户群体。
组件间的交互和数据流动均通过HDFS进行,确保了数据处理的一致性和高效性,HBase作为NoSQL数据库,直接从HDFS中读取和写入数据,与MapReduce任务无缝对接。
尽管MapReduce不再是唯一的计算框架(如Spark等新兴框架的崛起),它仍然是Hadoop生态中不可或缺的一部分,特别是在数据批量处理方面。
2、技术限制与优化:
MapReduce的主要限制在于处理实时计算和依赖关系的计算任务(如DAG计算)时性能不佳,这促使了其他技术如Tez和Storm等的发展来弥补这些不足。
分区组件Partitioner是MapReduce的一个重要优化手段,它允许用户自定义数据分区逻辑,从而优化数据处理过程中的网络传输和负载均衡。
在处理极大的数据集时,MapReduce的容错性和扩展性显得尤为重要,JobTracker和TaskTracker的结构确保了任务可以在成千上万的节点上顺利运行,即使部分节点失败也不会影响整个作业的完成。
MapReduce的输入数据集是静态的,不支持动态变化的流式数据,这限制了其在实时分析场景的应用,针对这一点,业界已发展出更多适合流式处理的工具和技术。
随着应用需求的变化和技术的发展,MapReduce虽面临挑战,但其在大数据教育和研究领域的基础地位依旧稳固,许多新的技术和框架也是在其基础上的扩展和改进。
Hadoop与MapReduce之间存在着密切且互补的关系,Hadoop提供了一个完善的生态系统,以支持大规模的数据存储和计算,而MapReduce是这个生态系统中关键的计算模型,负责执行实际的数据处理任务,这种关系确保了数据处理的高效性和系统的可扩展性,随着技术的不断进步和应用需求的多样化,MapReduce虽显示出一定的局限性,但其在批处理和教育研究中的应用仍使其保持着不可替代的地位,对于企业和研究机构而言,理解这种关系有助于更好地利用Hadoop生态系统进行大数据处理。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/865142.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复