


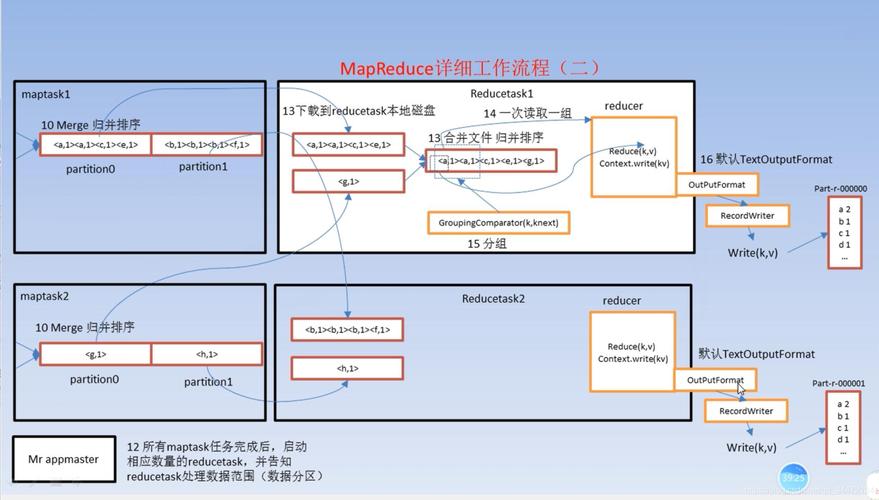
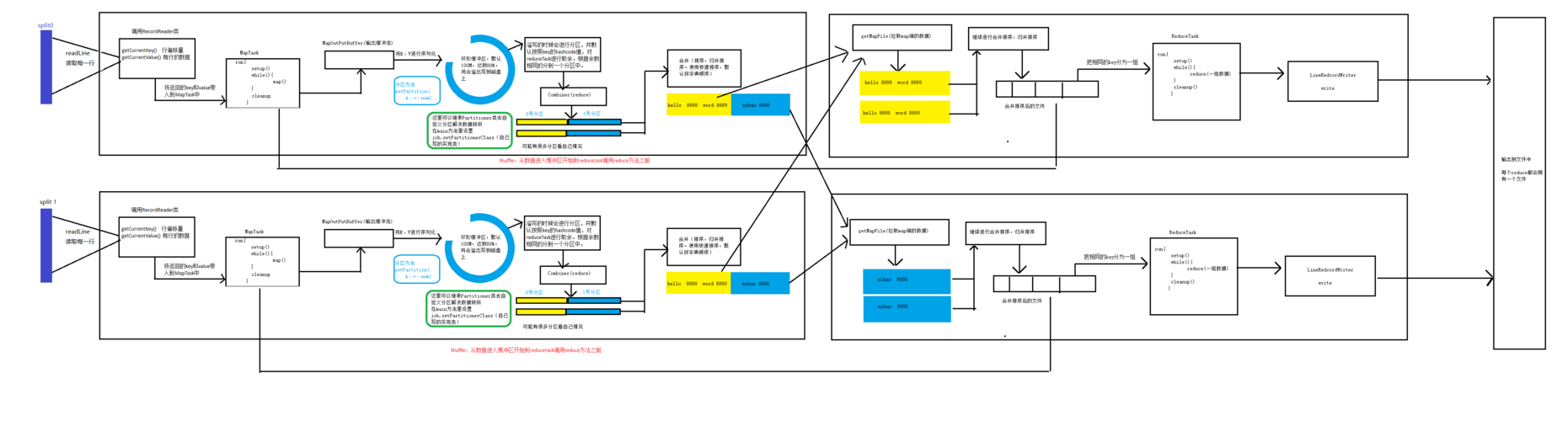
在大数据领域,MapReduce是一个广泛使用的编程模型,用于处理和生成大规模数据集,运行MapReduce作业通常涉及到将作业打包成JAR文件,并通过特定的命令提交到集群上执行,这个过程包括准备环境、打包、提交作业以及监控其运行状态,具体分析如下:

1、前期准备工作
环境配置:确保Hadoop环境已正确安装并配置,同时保证网络连接正常,以便与集群节点通信。
代码编写:开发MapReduce程序,包括map函数和reduce函数的编写,以及主函数main的实现。
2、打包MapReduce程序
使用IDE打包:在集成开发环境(如Eclipse或IntelliJ IDEA)中,通过导出功能将项目打包成JAR文件,在导出设置中指定主类,并选择JAR作为输出格式。
命令行打包:使用javac编译.java文件,然后使用jar命令手动打包成JAR文件。jar cvf myprogram.jar *.class 将编译后的所有类文件打包成一个JAR文件。
3、上传JAR文件到集群

连接到集群:使用SSH工具(如Xshell)连接到集群中的一个节点,通常选择具有足够权限的节点进行操作。
上传文件:利用SCP或其他文件传输工具将打包好的JAR文件上传到集群节点上。
4、提交MapReduce作业
使用hadoop jar命令:通过hadoop jar命令提交作业,指定JAR文件的位置、主类以及输入输出路径,例如hadoop jar myprogram.jar com.example.MyMainClass input output。
配置资源和环境:可以配置作业运行时需要的资源文件,如配置文件、依赖库等,可以通过设置环境变量来优化作业的运行。
5、监控和调整
查看作业状态:通过Yarn UI或Hadoop提供的其他命令查看作业的运行状态和进度。
日志分析:分析MapReduce作业的日志,以便于调试和优化作业设置。
在深入了解了MapReduce作业的运行机制后,以下这些因素也需要特别关注以避免常见的问题:
确保所有需要的类和资源都包含在JAR文件中。
正确配置资源副本数量和作业优先级,以优化集群资源使用。
监控作业运行时的资源使用情况,避免资源瓶颈。
运行一个MapReduce作业涉及多个步骤,从开发、打包到提交和监控,每一个环节都需要细致的注意,理解这些基本的操作步骤和注意事项,有助于更高效地在Hadoop集群上运行MapReduce作业,进而处理和分析大规模数据集。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/864581.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复