


MapReduce是一种编程模型,用于大规模数据处理,它允许开发者只需关注Map和Reduce两个函数的实现,而无需处理并行计算的细节,从而简化了并行程序的开发,下面将深入探讨如何开发MapReduce应用,包括实现Mapper和Reducer抽象类、任务配置和执行等关键步骤:

1、实现Mapper抽象类
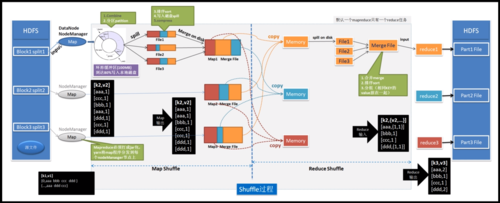
理解Mapper的角色:在MapReduce框架中,Mapper负责读取原始数据并产生中间键值对,此阶段是数据处理的开始,每个Mapper任务通常处理一个数据分片。
继承和重写方法:开发者需要继承Mapper类并重写map()方法,在Map方法中,开发者需定义如何处理每一行输入数据,并产生相应的输出键值对。setup()方法可用于初始化一些资源,如数据库连接或配置文件加载。
2、实现Reducer抽象类
理解Reducer的角色:Reducer的任务是接收来自多个Mappers的中间数据,并根据key进行聚合,处理完的数据将作为最终结果输出。
继承和重写方法:类似于Mapper, Reducer需要通过继承Reducer类并实现reduce()方法,在reduce()方法中,开发者需要编写逻辑来处理输入的键值对,通常是对相同key的value进行汇总或加工。
3、MapReduce作业配置
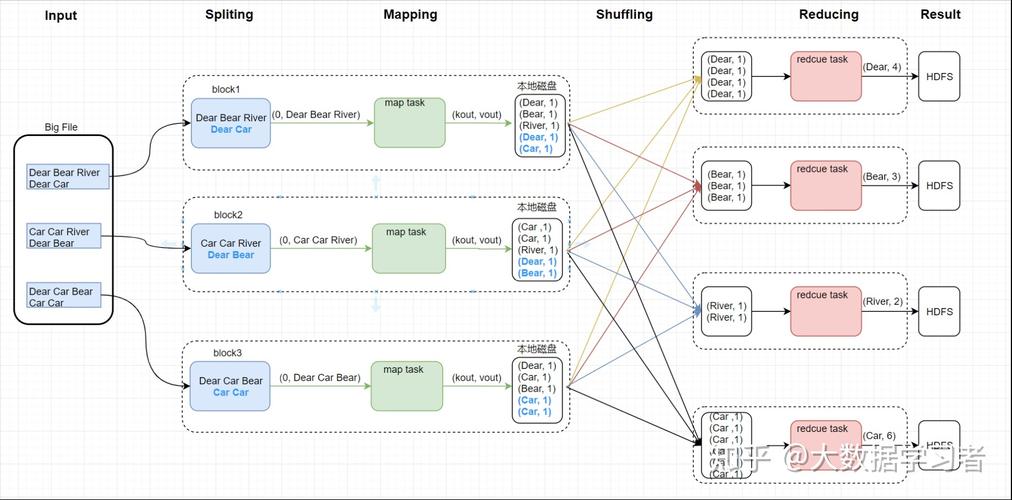
作业设置:创建一个MapReduce作业需要进行多方面的配置,包括但不限于设置作业名称、输入输出格式、Mapper和Reducer类等,这些设置确保了作业能正确运行并产生期望的结果。
详细配置:还需配置一些其他参数,如输入输出路径、文件格式(如TextInputFormat, SequenceFileInputFormat等)、数据压缩设置等,这些详细的配置有助于优化作业性能和资源使用。
4、提交和执行MapReduce作业
作业提交:配置好作业后,下一步是提交作业到Hadoop集群,这通常通过调用Job.waitForCompletion(Job)实现,它会提交MapReduce作业并等待其完成。
执行监控:在作业执行期间,应监控其状态和进度,以便及时发现并解决可能出现的问题,大多数Hadoop平台提供了用户界面来跟踪和管理运行中的作业。
5、优化和调试
性能调优:根据作业的运行表现,可能需要对MapReduce作业进行调优,以提高其效率和性能,这可能涉及调整数据分片大小、内存配置、并发任务数等参数。
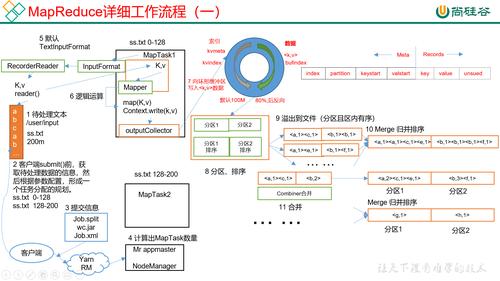
问题调试:如果作业执行出现问题,需要查看日志文件来识别和解决问题,常见的问题包括数据倾斜、网络瓶颈、内存溢出等。
MapReduce应用开发不仅涉及实现Mapper和Reducer类,还包括合理配置和优化MapReduce作业,以及有效管理和监控作业执行,通过遵循上述规则和最佳实践,开发者可以有效地开发出强大且可靠的MapReduce应用程序,以支持大规模的数据处理需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/864303.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复