


MapReduce作为一种高效的编程模型,专门用于处理大规模数据集,在处理海量数据时,如何实现任务的高效、均衡分配至关重要,这就是负载均衡的用武之地,本文将深入探讨MapReduce中的负载均衡技术,旨在全面理解其机制、实现方法及其对提高数据处理效率的影响。
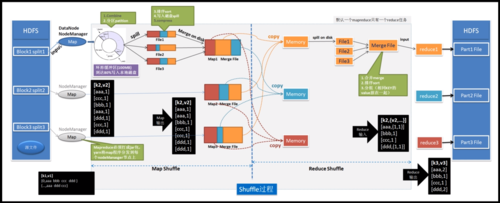

MapReduce基本概念
MapReduce编程模型主要包括两个阶段:Map阶段和Reduce阶段,简单地说,Map阶段的任务是将输入数据分解成独立的数据块,然后由不同的节点并行处理;而Reduce阶段的任务是汇总所有Map阶段的输出结果,以生成最终的输出。
负载均衡的重要性
在分布式计算中,特别是在处理大规模数据集时,不同节点的处理能力差异可能导致部分节点过载,而其他节点则可能处于空闲状态,负载均衡的目的是通过合理分配计算任务,优化资源使用,从而避免资源的浪费,提高系统的总吞吐量和响应速度。
MapReduce中的负载均衡技术
随机流体动力负载平衡技术
这种技术主要依赖于数据的随机分配和动态调整,在MapReduce框架下,通过将输入数据随机分配给各个Map节点,可以在一定程度上保证每个节点的初始工作负载是均衡的,随后,根据各节点的处理速度和当前负载情况,系统会动态调整任务分配,以达到一个相对平衡的状态。
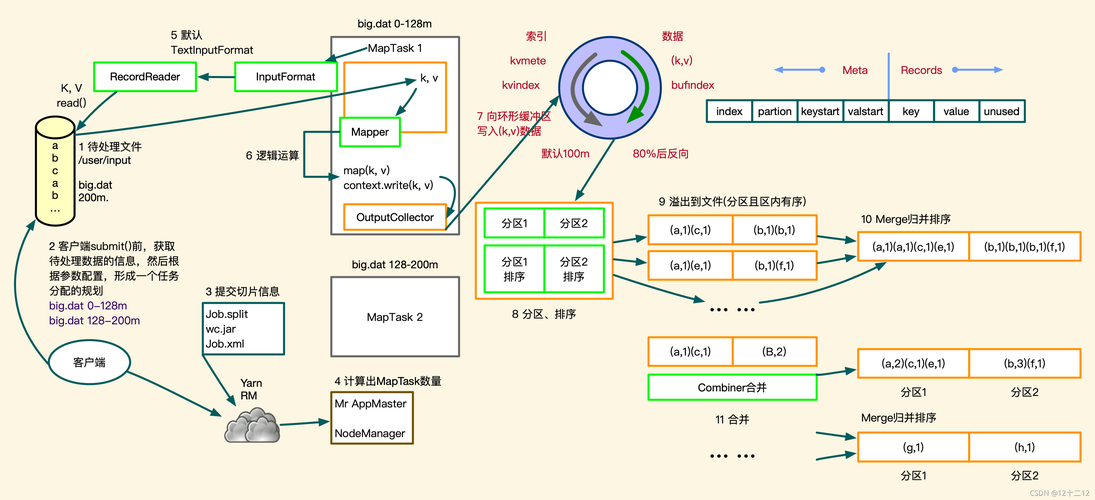
数据本地化优化
为了进一步减少网络传输造成的延迟,提高数据处理速度,MapReduce框架会尽量将数据处理任务分配给数据存储位置附近的节点进行处理,这种方法称为“数据本地化”,它可以显著提高大数据处理的效率,尤其是在数据传输成本较高的场景下。
自适应负载均衡策略
随着计算任务的执行,某些节点可能会因为各种原因(如硬件性能差异、数据倾斜等)出现处理速度慢的情况,自适应负载均衡策略能够根据实时监控到的各节点处理进度,动态地重新分配部分任务,确保所有节点都能高效运行,避免单个节点成为性能瓶颈。
负载均衡对MapReduce性能的提升
通过实施负载均衡技术,MapReduce作业可以在更短的时间内完成,同时系统的资源利用率也得到显著提升,在云环境中,MapReduce配合负载均衡技术可以显著提高大数据集处理的吞吐量,而在非云系统中,虽然负载均衡对吞吐量的提升效果可能不那么明显,但对于提高系统稳定性和资源利用率仍然具有重要意义。
负载均衡的挑战与对策
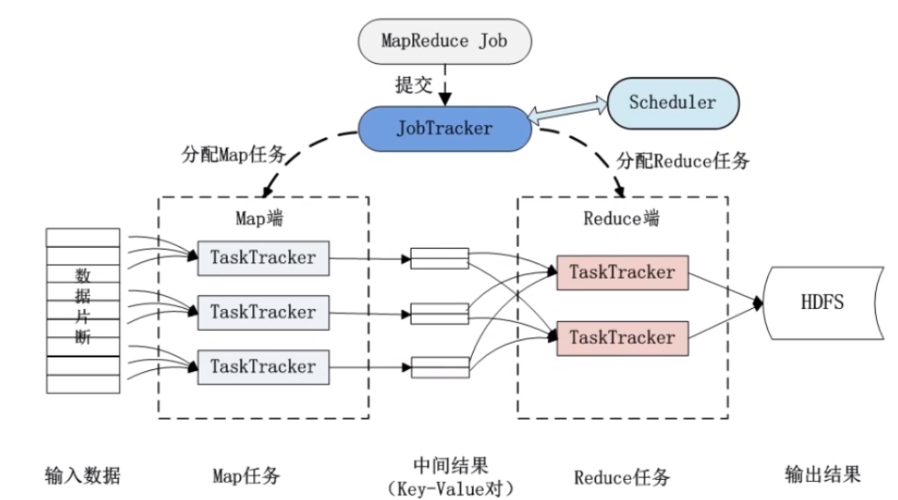
尽管负载均衡技术为MapReduce带来了诸多好处,但在实际应用中仍面临一些挑战,如数据倾斜问题、任务调度策略的复杂性以及动态环境下的适应性问题,针对这些挑战,可以通过优化数据划分方式、设计更智能的任务调度算法以及引入机器学习等技术来提高负载均衡机制的有效性和自适应性。
上文归纳与展望
MapReduce作为一种高效的大数据处理框架,在全球范围内得到了广泛应用,而负载均衡技术作为其性能提升的重要手段之一,通过合理的任务分配和资源优化,显著提高了数据处理的效率和系统的稳定性,随着数据量的持续增长和技术的不断进步,负载均衡技术也将持续发展,以应对更加复杂的数据处理需求和更大规模的数据挑战。
###
通过以上深入分析,我们可以看到,负载均衡技术对于提升MapReduce框架下数据处理的性能和效率具有不可忽视的作用,让我们通过一些相关问答进一步加深理解。
FAQs
MapReduce负载均衡有哪些常见策略?
答:常见的MapReduce负载均衡策略包括随机流体动力负载平衡技术、数据本地化优化以及自适应负载均衡策略,这些策略旨在通过不同机制实现任务的合理分配和资源的高效利用。
如何评估MapReduce负载均衡的效果?
答:评估MapReduce负载均衡的效果可以从多个维度进行,包括但不限于系统吞吐量、资源利用率、任务完成时间以及系统的稳定性等,具体评估方法包括数据分析、性能监控以及对比测试等。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/864226.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复