


MapReduce模型是处理大规模数据中一种常用的分布式计算框架,在实际应用中,单词计数是一个常被引用的例子,用于演示如何使用MapReduce进行数据处理,本文将深入探讨使用MapReduce进行单词统计的过程,包括代码实例和操作步骤,帮助读者更好地理解和应用这一技术。
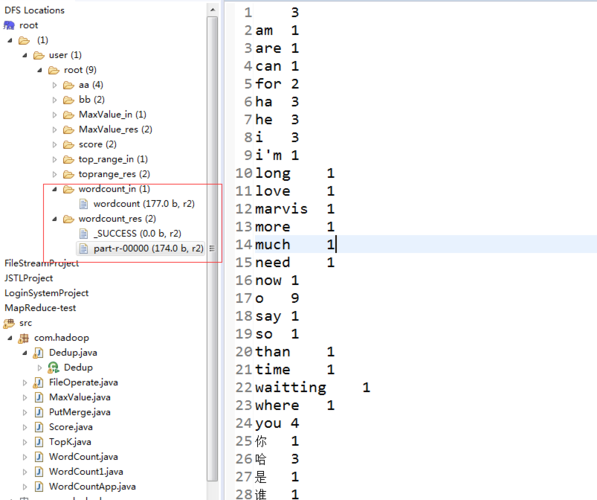

前情提要
在开始介绍MapReduce的单词统计之前,我们需确保已经配置好了Hadoop环境以及相关开发工具,如Eclipse,并了解MapReduce的基本API调用方法,这包括对Mapper和Reducer的基本理解,以及如何编写和运行一个MapReduce作业。
前置条件
在具体编写代码之前,需要确认几个前置条件已经被满足,确保Hadoop集群已经正确安装和配置,开发环境(例如Eclipse)应该配置好,以便能够编译和运行MapReduce程序,对于Java编程语言有一定的了解也是必须的,因为Hadoop MapReduce框架是用Java编写的。
创建Maven工程
为了管理项目依赖和构建过程,建议创建一个Maven工程,通过Maven,可以轻松添加Hadoop的依赖库到项目中,简化构建和部署过程。
修改Windows系统变量
如果是在Windows环境下进行开发,需要修改系统环境变量,添加JAVA_HOME和HADOOP_HOME,指向正确的Java和Hadoop安装路径,这一步确保可以在命令行中执行Java和Hadoop命令。
编写MapReduce的JAR文件
我们将深入到代码的编写,在Map阶段,Mapper的任务是将输入数据(例如文本文件)分割成单个单词,并输出每个单词及其出现次数的中间键值对,这个过程通常伴随着数据清洗,比如将文本转换为小写,去除标点符号等。
1. Map阶段的核心处理逻辑
输入: 文本文件块
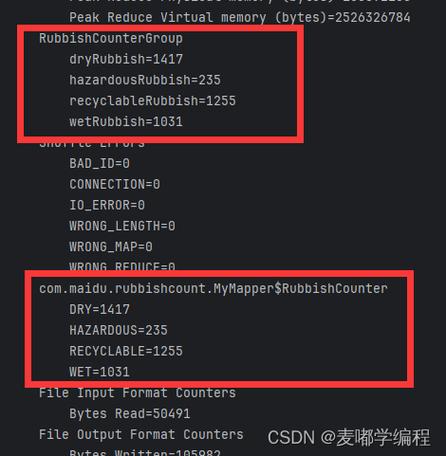
处理: 切分、清洗文本数据
输出: (单词, 1) 对
在Reduce阶段,Reducer的工作是接收所有相同键(单词)的中间键值对,合并它们的值(即统计总数),最终输出每个单词的总计次数。
2. Reduce阶段的核心处理逻辑
输入: 来自Mapper的(单词, 1) 对
处理: 累加同一单词的出现次数
输出: (单词, 总次数) 对
将编写好的Mapper和Reducer组合成一个Job,并对Job进行设置,包括输入输出格式设置、Mapper和Reducer类设置等,提交Job到Hadoop集群执行,得到最终的单词统计结果。
执行MapReduce作业
作业配置完成后,通过Hadoop命令行工具提交作业到集群,监控作业的进度,查看统计结果是否正确,如果一切顺利,最终将在输出路径下看到每个单词及其出现次数的列表。
FAQs
Q1: 如何处理不同编码的文本文件?
A1: 在读取文件时,确保使用与文件匹配的字符编码,可通过配置FileInputFormat的Path对象实现。
Q2: MapReduce作业运行缓慢怎么办?
A2: 优化可能涉及多方面,包括但不限于增加Reducer的数量、调整Hadoop配置参数、优化数据分布等。
通过上述步骤和指南,用户应能成功利用MapReduce进行单词统计,这不仅展示了MapReduce在处理大数据场景下的强大能力,同时也提供了实际编程和应用的重要经验,希望本文能够帮助读者深入理解并有效使用MapReduce技术。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/863969.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复