


MapReduce框架是一个分布式运算的编程框架,用于处理和生成大数据集,它适用于大量数据的并行处理,通过将任务分配给多个节点,可以显著提高数据处理速度,下面将详细解析MapReduce框架的主要组成部分及其工作机制:
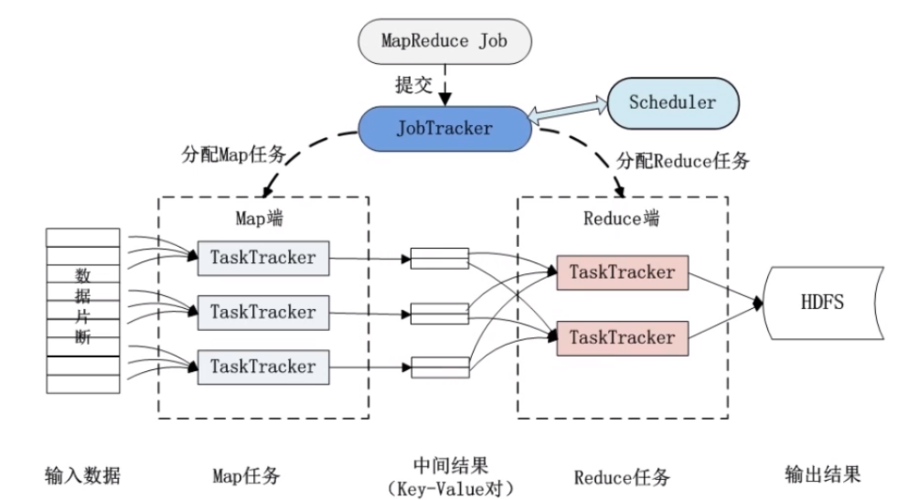

1、框架
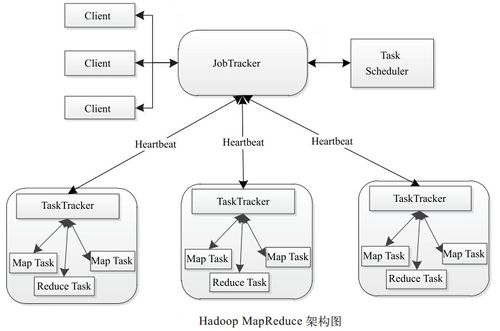
基础架构:MapReduce采用Master/Slave架构,包括一个Master节点和多个Slave节点,Master节点负责管理整个MapReduce作业的运行,而Slave节点则执行实际的任务。
核心功能:MapReduce的核心功能是将用户编写的业务逻辑代码与框架自带的默认组件整合,形成一个完整的分布式运算程序,并发运行在Hadoop集群上。
2、进程与节点
JobTracker:运行在Master节点上的JobTracker负责调度作业、监控任务的执行以及处理失败任务。
TaskTracker:运行在Slave节点上的TaskTracker负责执行具体的Map或Reduce任务,并向JobTracker报告进度和状态。
3、编程模型
Map函数:用户需要实现的Map函数,用于处理输入数据并生成一系列中间键值对。
Reduce函数:同样由用户实现的Reduce函数,用于处理Map函数输出的中间键值对,并输出最终结果。
4、工作流程
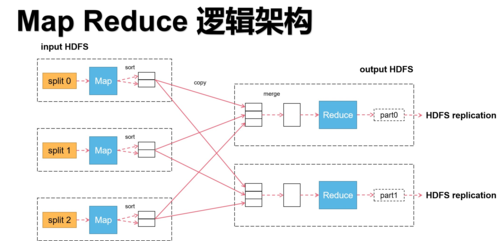
输入分片:输入数据被分成若干个数据片段,每个数据片段由一个Map任务处理。
Map阶段:每个Map任务根据用户定义的Map函数处理数据片段,生成中间键值对。
Shuffle和Sort阶段:框架自动对Map的输出进行排序和分组,确保每个键的所有值都发送到同一个Reduce任务。
Reduce阶段:Reduce任务对每个键调用一次用户定义的Reduce函数,输出最终结果。
5、容错机制
任务失败处理:如果TaskTracker报告任务失败或过长时间无响应,JobTracker会在其他Slave节点上重新调度执行失败的任务。
数据备份:Hadoop的HDFS为了应对硬件故障,会将数据块复制到多个节点,确保数据的高可用性。
6、应用范围
适用场景:适用于需处理TB至PB级别数据的场景,如日志分析、数据挖掘等。
不适用场景:对于实时处理要求高或数据量较小的应用场景,MapReduce可能不是最佳选择。
为进一步了解MapReduce框架的实际应用及性能优化,可以考虑以下几点信息:
Hadoop框架是用Java实现的,但MapReduce应用程序也可以使用其他语言编写,如Python、Ruby等。
合理配置Map和Reduce任务的数量,根据集群的实际能力和作业的复杂度调整,可以优化作业执行效率。
确保输入数据均匀分布,避免某些Map或Reduce任务处理的数据量过大,影响整体作业执行时间。
MapReduce框架通过其分布式处理能力,为用户提供了强大的数据处理能力,通过详细了解其工作原理和特点,用户可以更有效地利用这一框架处理大规模数据,从而推动数据分析和数据驱动决策的发展。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/862897.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复