


MapReduce连接HBase可以实现强大的数据处理功能,在MapReduce中使用HBase作为数据源或结果输出,可以有效处理和分析大量数据,这个联合操作不仅加速了数据处理过程,还增强了数据的可访问性和可操作性,下面将深入探讨如何通过各个步骤实现这一技术:
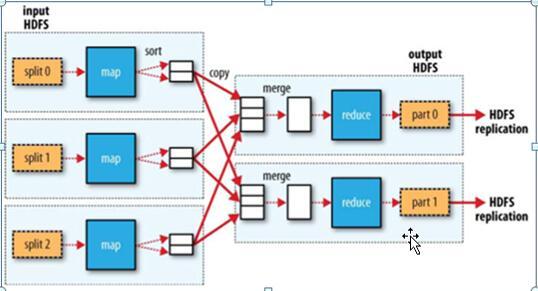

1、环境配置
启动服务:确保HDFS和HBase服务正在运行,这可以通过执行startdfs.sh和starthbase.sh脚本来实现。
配置文件设置:为了使MapReduce能够访问HBase,需要适当地配置环境,这包括添加hbasesite.xml到$HADOOP_HOME/conf和将HBase jars添加到$HADOOP_HOME/lib目录。
权限授予:确保部署在MapReduce集群中的任务有权限读取HBase数据和配置,避免安全限制影响任务执行。
2、编程实现
项目建立与依赖添加:在Eclipse中创建一个新的Java Project,并添加必要的HBase库和jar文件,这一步是编写和运行MapReduce程序的基础,确保程序能正确识别和使用HBase的API。
编写Mapper和Reducer:编写Mapper类来处理HBase的数据读入和处理,同样,Reducer类用于处理Mapper的输出,并得出最终结果,这两个类的实现是整个数据处理流程的核心。

Driver配置:在Driver中设定作业配置,包括输入输出格式、表名和列族等,也需在此设置Mapper和Reducer类。
3、数据处理
读取HBase数据:使用TableInputFormat从HBase中读取数据,这个格式允许MapReduce直接与HBase数据交互,而无需中间文件的转换。
写入HBase数据:处理后的数据可以通过TableOutputFormat写回HBase,这样做可以使得数据更新回到HBase表中,供后续使用或查询。
4、实际应用
词频统计案例:一种常见的应用是进行词频统计,在这个例子中,MapReduce任务会读取存储在HBase中的文本数据,计算每个单词的出现频率,并将结果写回到HBase中。
实时数据分析:对于需要快速读写访问的场景,如实时数据分析,HBase和MapReduce的结合提供了可能,在电商系统中分析用户行为,实时更新数据。
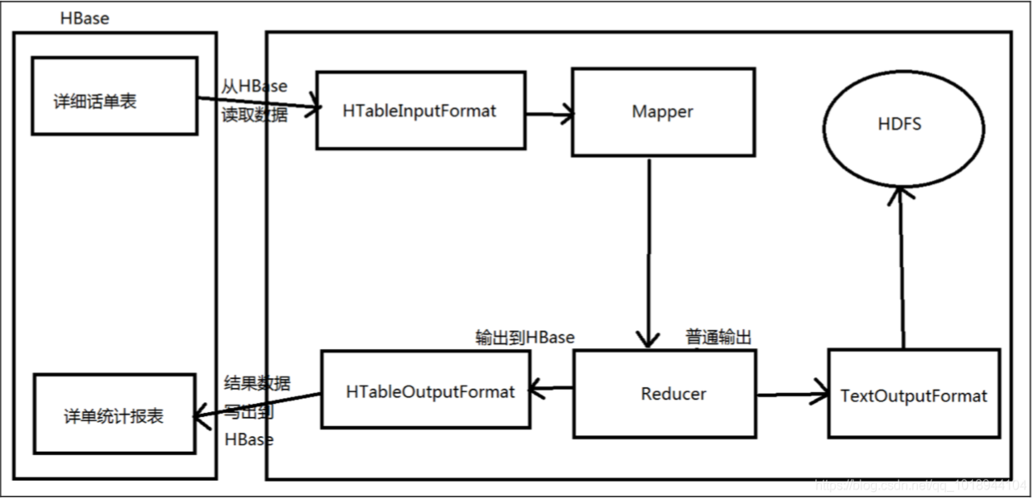
5、问题与调试
性能优化:监控MapReduce任务的性能,根据需要调整HBase的区域设置,以优化读写效率。
错误处理:合理配置日志,快速定位和解决在数据处理过程中遇到的问题,如数据不一致或处理延迟。
在了解上述内容后,还可以关注以下几个方面:
确保所有节点上HBase和Hadoop之间的兼容性,避免因版本不兼容导致的问题。
考虑到数据安全和完整性,定期备份HBase数据,以防数据丢失或损坏。
使用适当的压缩算法来减少存储需求和提高数据处理速度。
适时更新HBase和Hadoop系统,以利用最新的功能和性能改进。
结合MapReduce和HBase可以极大地增强数据处理的能力,不仅提高了处理速度,还增加了处理大规模数据集的灵活性,通过正确配置环境和仔细规划数据处理逻辑,可以有效地实现数据的读取、处理和写回,这种技术组合为大数据解决方案提供了一种强大且可扩展的框架,特别适用于需要快速读写和实时分析的应用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/862189.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复