


在MapReduce编程模型中,排序(Sort)和键分组(Grouping by key)是两个重要的步骤,对于提高数据处理效率至关重要,本文主要介绍如何在MapReduce中进行排序和键分组操作,并给出一个示例来说明这两个过程的实现。

MapReduce 排序和键分组简介
MapReduce是一种用于大规模数据集(大于1TB)并行运算的编程模型,它的核心思想是将大任务分解为多个小任务,这些小任务可以同时在不同的节点上运行,然后再将结果合并,在这个过程中,排序和键分组是两个关键的步骤。
排序(Sort)
在MapReduce中,排序通常发生在两个阶段:Map阶段的输出排序和Reduce阶段的输入排序,Map阶段的输出排序是为了提高数据传输效率,而Reduce阶段的输入排序则是为了确保Reduce函数能够按照键值对(keyvalue pair)的顺序处理数据。
键分组(Grouping by Key)
键分组是指将具有相同键值的数据聚合在一起,以便Reduce函数可以对每个键值进行处理,在MapReduce中,键分组通常与排序一起使用,以确保Reduce函数能够按照键值对的顺序处理数据。
MapReduce 排序和键分组实现
在MapReduce中,排序和键分组的实现主要依赖于以下几个步骤:
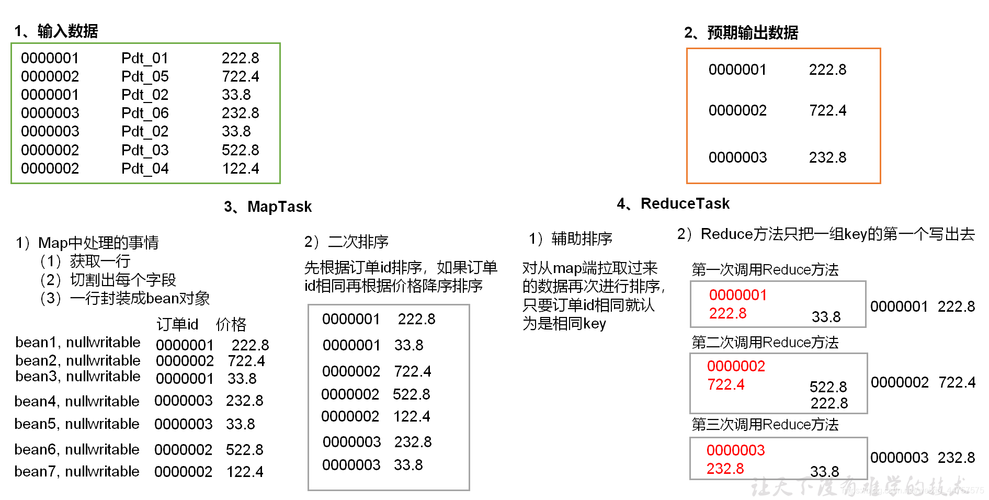
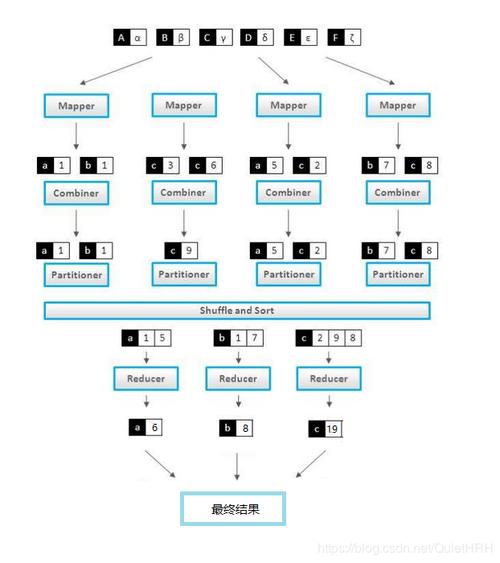
1、Map阶段:Map函数处理输入数据,生成一系列键值对,然后对这些键值对进行本地排序和键分组,以便于后续的数据传输和处理。
2、Shuffle阶段:Shuffle阶段负责将Map阶段的输出数据传输到Reduce阶段,在这个阶段,数据会根据键值进行排序和分组。
3、Reduce阶段:Reduce函数接收到排序和分组后的数据,然后按照键值对的顺序进行处理。
下面是一个使用Java编写的简单MapReduce程序示例,用于计算文本中单词的出现次数:
public class WordCount {
public static class Map extends MapReduceBase implements Mapper<LongWritable, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(LongWritable key, Text value, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
String line = value.toString();
StringTokenizer itr = new StringTokenizer(line);
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
output.collect(word, one);
}
}
}
public static class Reduce extends MapReduceBase implements Reducer<Text, IntWritable, Text, IntWritable> {
public void reduce(Text key, Iterator<IntWritable> values, OutputCollector<Text, IntWritable> output, Reporter reporter) throws IOException {
int sum = 0;
while (values.hasNext()) {
sum += values.next().get();
}
output.collect(key, new IntWritable(sum));
}
}
public static void main(String[] args) throws Exception {
JobConf conf = new JobConf(WordCount.class);
conf.setJobName("wordcount");
conf.setOutputKeyClass(Text.class);
conf.setOutputValueClass(IntWritable.class);
conf.setMapperClass(Map.class);
conf.setCombinerClass(Reduce.class);
conf.setReducerClass(Reduce.class);
conf.setInputFormat(TextInputFormat.class);
conf.setOutputFormat(TextOutputFormat.class);
FileInputFormat.setInputPaths(conf, new Path(args[0]));
FileOutputFormat.setOutputPath(conf, new Path(args[1]));
JobClient.runJob(conf);
}
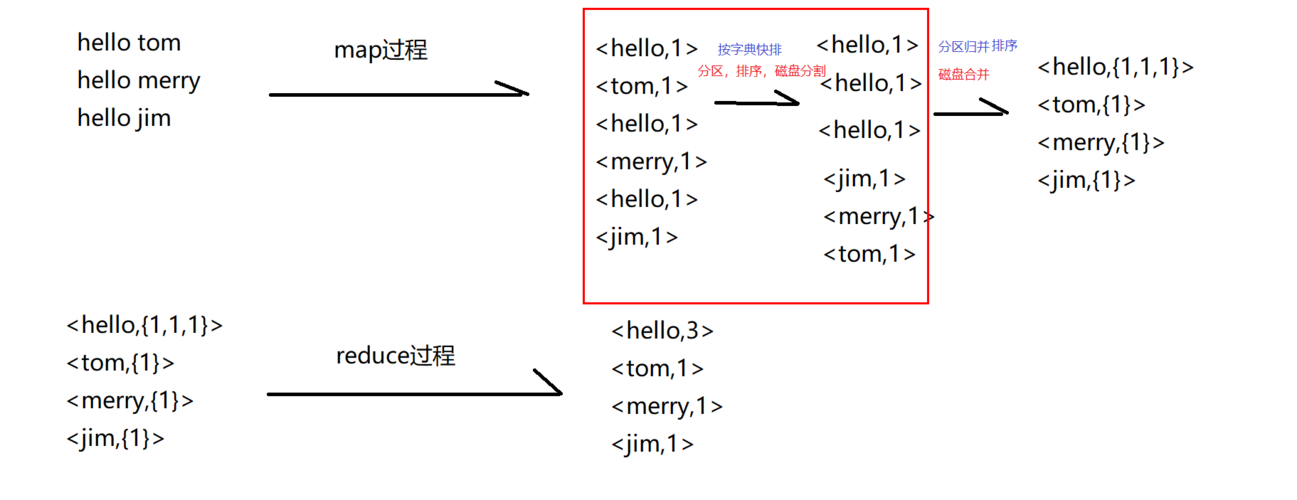
} 在这个示例中,Map函数将输入文本分割成单词,并为每个单词生成一个键值对(单词,1),这些键值对会在Shuffle阶段进行排序和分组,Reduce函数会按照键值对的顺序计算每个单词的出现次数。
相关问答FAQs
Q1: MapReduce中的排序和键分组是否可以自定义?
A1: 是的,MapReduce允许用户自定义排序和键分组的逻辑,这可以通过实现自定义的Partitioner类来实现。Partitioner类负责将Map阶段的输出数据分发到不同的Reduce任务,通过实现自定义的Partitioner类,用户可以控制数据的分发策略,从而实现自定义的排序和键分组逻辑。
Q2: MapReduce中的排序和键分组对性能有何影响?
A2: 在MapReduce中,排序和键分组对性能有很大的影响,排序可以提高数据传输的效率,因为具有相同键值的数据会被传输到同一个Reduce任务,键分组可以确保Reduce函数按照键值对的顺序处理数据,从而提高数据处理的效率,排序和键分组也会带来一定的计算和存储开销,在设计MapReduce程序时,需要权衡排序和键分组带来的性能提升与开销之间的关系。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/862185.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复