

在大数据框架中,关联两个数据表是一项常见的需求,尤其是在处理结构化数据时,MapReduce框架下的数据表关联操作通常涉及到两个主要步骤:Map步骤和Reduce步骤,下面将详细探讨如何通过MapReduce实现两表关联,特别是关联子表的操作:
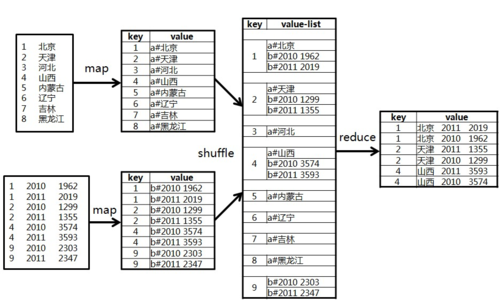
Map步骤
1、数据读取与分发
数据源准备:首先需要有两个数据源,即主表和需要关联的子表,这些数据通常存储在HDFS等分布式文件系统中。
数据读取:在Map阶段开始时,Map任务会分别读取这两个表中的数据。
数据标记与分发:为了区分来自不同表的数据,Map函数在输出数据时会打上标记,可以给主表的每条记录添加tag_main,给子表的每条记录添加tag_sub。
2、数据预处理
格式转换:将读取的数据处理成<key, value>对的格式,其中key是关联字段(如ID),value则是包括了表中其他所有列的列表。
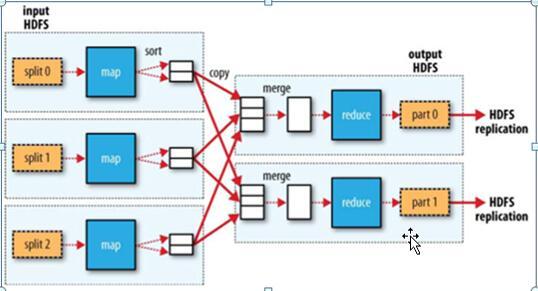
标记识别:确保每个<key, value>对中包含了来源表的标记信息,便于Reduce阶段进行正确的关联操作。
3、数据输出
Key的选择:选择合适的Key是关键,这通常是两个表中共有的字段,用于后续的关联操作。
中间数据生成:Map函数输出的中间数据将被用于Reduce阶段,数据的格式通常为<key, {valueMain, valueSub}>。
Reduce步骤
1、数据接收与分类
接收中间数据:Reduce函数接收到的输入是Map输出的键值对,格式为<key, {valueMain, valueSub}>。
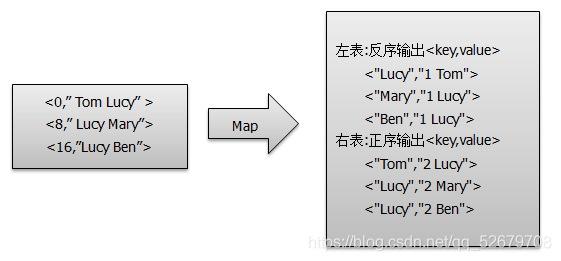
提取与分类:根据标记信息将接收到的数据分类到不同的列表中,如listMain和listSub。
2、关联逻辑实现
笛卡尔积应用:使用笛卡尔积操作来关联listMain和listSub中的数据,这一步将产生所有可能的组合。
去重与过滤:在实际应用中,可能需要去除重复的关联结果或根据业务逻辑过滤掉不符合条件的记录。
3、结果输出
格式化输出:将关联后的结果格式化,输出成为最终的关联结果,可以直接写入到HDFS或其他存储系统中。
性能优化:考虑到数据倾斜的问题,应合理设计Reduce函数以平衡各个节点的负载,避免某些节点因数据量过大而成为性能瓶颈。
以下是一些在执行MapReduce两表关联时需要考虑的关键因素:
数据倾斜问题:在进行大数据处理时,需警惕数据倾斜导致的处理效率问题,考虑采用如Map侧join、在Reduce之前进行局部聚合等策略来优化。
容错性与可扩展性:确保MapReduce作业在遇到硬件故障时能够自动恢复,同时保证在数据量增加时能有效地扩展处理能力。
网络带宽使用:尽量减少在Map和Reduce之间的数据传输量,这通常通过在Map阶段进行本地聚合来实现。
MapReduce中的两表关联操作涉及多个细节和考量,从数据的读取、预处理到最终的关联和结果输出,每一步都需要精确的设计和优化,通过高效实施这些步骤,可以有效处理大规模数据集的关联需求,支持复杂的数据分析任务。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/862083.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。