


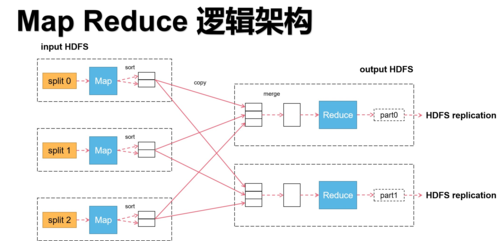
MapReduce是一种编程模型,用于处理大规模数据集,它的核心思想是将一个大任务分解成多个小任务,这些小任务可以并行处理,然后将结果合并得到最终结果,MapReduce通常用于分布式计算环境,如Hadoop,下面是一些使用MapReduce处理的场景。
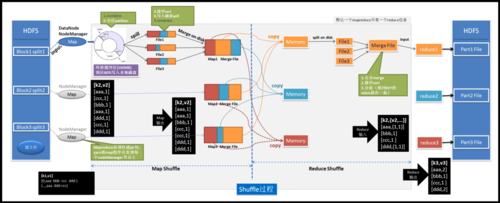

1. 单词计数
这是一个经典的MapReduce示例,假设我们有一个大型文本文件,我们想要计算每个单词出现的次数。
Map阶段
输入:原始文本文件
处理:将文本分割成单词,并为每个单词生成一个键值对(单词,1)
输出:键值对列表,"apple", 1),("banana", 1),("apple", 1)等
Reduce阶段
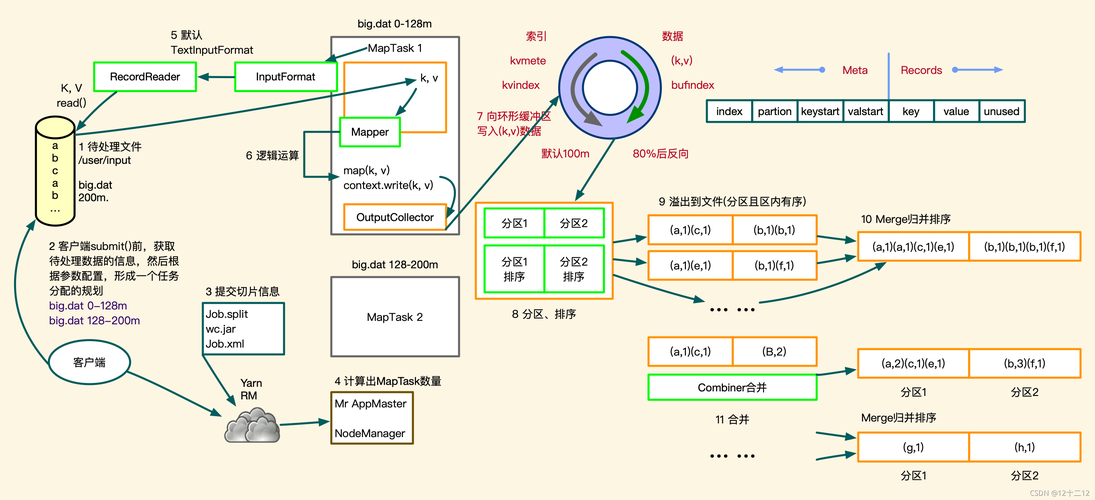
输入:Map阶段的输出键值对
处理:对相同的键(单词)进行聚合,累加值
输出:每个单词及其出现次数,"apple", 2),("banana", 1)
2. 日志分析
在服务器日志文件中,我们可能需要找出访问量最大的页面。
Map阶段
输入:日志文件
处理:解析每条日志记录,提取页面URL和访问时间
输出:键值对列表,"/home", 1),("/about", 1),("/contact", 1)等
Reduce阶段
输入:Map阶段的输出键值对
处理:对相同的键(URL)进行聚合,累加值
输出:每个URL及其访问次数,"/home", 100),("/about", 50),("/contact", 20)
3. 数据去重
假设我们有一个大型数据集,我们想要去除重复的数据项。
Map阶段
输入:原始数据集
处理:读取数据项,为每个数据项生成一个键值对(数据项,1)
输出:键值对列表,"apple", 1),("banana", 1),("apple", 1)等
Reduce阶段
输入:Map阶段的输出键值对
处理:对相同的键(数据项)进行聚合,保留一个实例
输出:去重后的数据项,"apple", 1),("banana", 1)
4. 连接操作
在数据库中,我们可能需要执行连接操作,例如将用户表和订单表连接起来以获取用户的订单信息。
Map阶段
输入:用户表和订单表
处理:为每个用户生成一个键值对(用户ID,用户信息),为每个订单生成一个键值对(用户ID,订单信息)
输出:两个键值对列表,"user1", "Alice"),("order1", "book"),("user1", "Bob"),("order2", "pen")等
Reduce阶段
输入:Map阶段的输出键值对
处理:对相同的键(用户ID)进行聚合,将用户信息和订单信息连接起来
输出:连接后的结果,"user1", ("Alice", ["book", "pen"])),("user2", ("Bob", ["pen"]))
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/861624.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复