


在当今大数据时代,MapReduce模型已成为处理大规模数据集的一种重要工具,C语言实现MapReduce引擎的核心在于理解其编程模型和接口设计,本文旨在深入分析如何用C语言实现一个MapReduce引擎,包括关键接口的设计和实现。
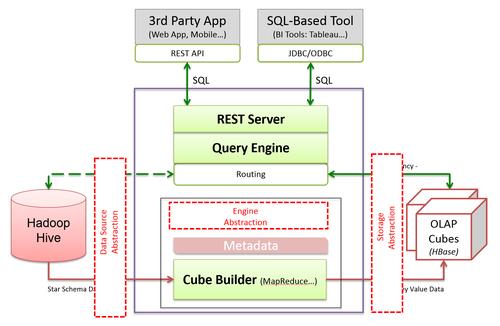

MapReduce的基本概念
MapReduce是一种编程模型,用于大规模数据处理,它的核心思想是将复杂的问题分解为两个阶段:Map阶段和Reduce阶段,Map函数处理输入数据,生成一组中间键值对;Reduce函数则负责合并所有具有相同键的值,这种模型的简单性使得程序员可以容易地并行化处理大规模数据集,而无需关注底层的并发管理。
C语言实现MapReduce引擎的必要性
C语言因其高效的性能和转换能力,在系统级编程中占有不可替代的地位,尽管像Hadoop这样的框架大多使用Java实现,但在一些需要高执行效率和低内存消耗的场景下,使用C语言实现MapReduce引擎显得尤为重要,对于嵌入式系统或特定的硬件平台,C语言实现的MapReduce引擎可以提供更好的性能优化空间。
核心组件和编程接口
1. Driver组件
Driver组件是整个MapReduce作业的入口点,它负责配置作业、控制Mapper和Reducer的数量以及管理作业的输入输出数据,在C语言实现中,Driver需要初始化相关参数,如内存分配策略、线程池大小等,并启动MapReduce流程。
2. Mapper接口
Mapper接口接收输入数据,通过用户定义的Map函数处理这些数据,并输出中间键值对,在C语言中实现此接口时,通常需要定义一个接受输入数据结构体,并返回一个包含键值对的结构体数组,考虑到效率和内存管理,使用指针和动态内存分配是常见的做法。
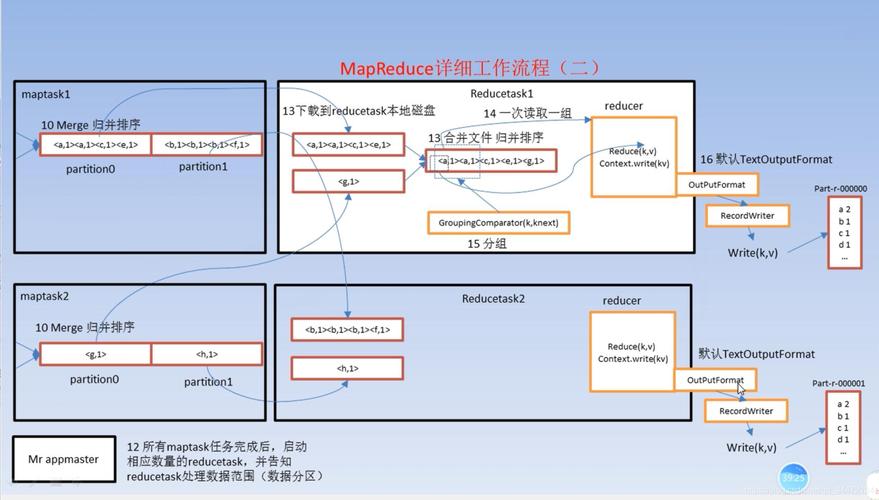
3. Shuffle和Sort
Shuffle是将Mapper的输出传输到Reducer的过程,Sort则是在此过程中进行的数据排序,在C语言实现中,这一步骤需要考虑内存和CPU资源的优化,可能采用多线程或异步I/O操作来提高数据传输的效率。
4. Reducer接口
Reducer接口的任务是接收来自Mapper经过Shuffle和Sort的中间数据,并通过用户定义的Reduce函数处理这些数据,在C语言实现中,这通常涉及到复杂的数据结构设计和算法优化,以确保数据处理的高效性和准确性。
5. Output组件
Output组件负责将Reducer的结果写回到文件系统或数据库,在C语言中,这可能涉及到文件操作或网络编程,确保数据的可靠存储和有效访问。
序列化和反序列化
在MapReduce中,数据的序列化和反序列化是不可或缺的一环,尤其是在不同节点间传输数据时,C语言实现中,开发者需确保自定义的数据类型能够被正确序列化和反序列化,这通常意味着需要手动实现序列化函数,或者使用如Protocol Buffers这类的库来帮助处理复杂的数据结构。
性能优化技巧
在C语言实现MapReduce时,性能优化是一个关键的考虑因素,这包括算法优化、内存访问模式优化、利用SIMD指令集等技术,合理的数据结构和精确的资源管理(如内存和线程)也是提升性能的重要途径,考虑到C语言的低层特性,开发者可以通过调整编译器优化选项来进一步挖掘性能潜力。
相关问答FAQs
Q1: 为什么在C语言中实现MapReduce比在其他高级语言中更有挑战性?
A1: C语言作为一种底层语言,提供了高度的内存和系统调用控制权,但这也意味着开发者需要手动管理内存分配和回收,处理并发和线程同步问题,这些都增加了编程的复杂性,缺乏自动垃圾回收机制使得资源管理更为严格,错误更可能导致程序崩溃。
Q2: 使用C语言实现MapReduce有哪些潜在的优势?
A2: 使用C语言可以实现更接近硬件的操作,减少额外抽象层的开销,从而在某些场景下提供更高的运行效率,C语言的可移植性强,可以在多种操作系统和硬件平台上运行,这使得C语言实现的MapReduce引擎可以灵活部署在从微型嵌入式设备到高性能计算集群的广泛环境中。
虽然在C语言中实现MapReduce引擎具有一定的复杂性,但凭借C语言的性能优势和灵活性,这种实现方式在特定需求下仍具有不可替代的优势,开发者在设计和实现过程中应充分注意接口设计、数据结构选择、并发控制及性能优化等方面,以确保最终系统的高效和稳定。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/861312.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复