


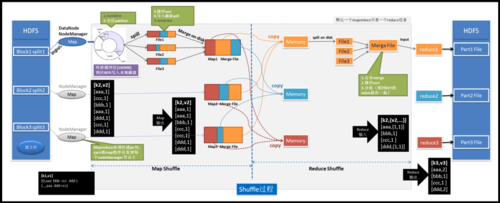
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算,它的核心思想是将问题分而治之,即将一个问题分解为多个小问题,然后分别解决后再合并结果,在聚类分析中,MapReduce可以有效地处理大量数据点,实现高效的数据聚类,下面将详细解析如何使用MapReduce进行URL聚类:

1、聚类算法选择
Kmeans聚类算法:这是一种广泛应用的聚类算法,其目标是将数据点划分为指定的K个簇,使得每个数据点归属于距离其最近的中心点所代表的簇。
算法特点:简单、易于理解和实现,适用于大规模数据集上的聚类任务。
算法流程:初始化中心点→分配数据点到最近的簇→更新中心点→重复上述过程直到收敛。
2、MapReduce角色定义
Mapper的任务:计算每条数据与中心点的距离,并将数据点分配给最近的簇。
Reducer的职责:接收Mapper的输出,对相同簇的数据点进行归并,并计算新的中心点。
3、数据处理流程
读取数据:Mapper首先读取原始数据,这些数据可以是URL或其它需要聚类的数据点。
计算距离:Mapper计算每条数据与各中心点的距离,这通常涉及向量空间模型和余弦相似度或其他距离度量标准。
4、迭代更新
分配簇:根据距离计算结果,Mapper将数据点分配给最近的簇,并以簇的ID作为key,数据点作为value输出。
更新中心点:Reducer汇总同一簇内的所有数据点,计算新的中心点,并判断是否达到收敛条件。
5、收敛条件判断
迭代终止:如果新旧中心点的差距小于预设的阈值或者迭代次数达到上限,则认为聚类过程收敛,算法结束。
6、优化与改进
并行化处理:MapReduce的本质是并行计算,它可以在多个节点上同时处理不同的数据分片,显著提高计算效率。
负载均衡:合理的数据划分和任务调度可以确保各个节点负载均衡,避免单个节点成为性能瓶颈。
使用MapReduce进行URL聚类不仅提高了处理大规模数据集的能力,而且通过分布式计算资源有效降低了计算时间,在实际应用中,可以根据具体需求调整Kmeans算法的参数以及MapReduce的运行环境,以达到最佳的聚类效果。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/861165.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复