


服务器运维过程中死机原因
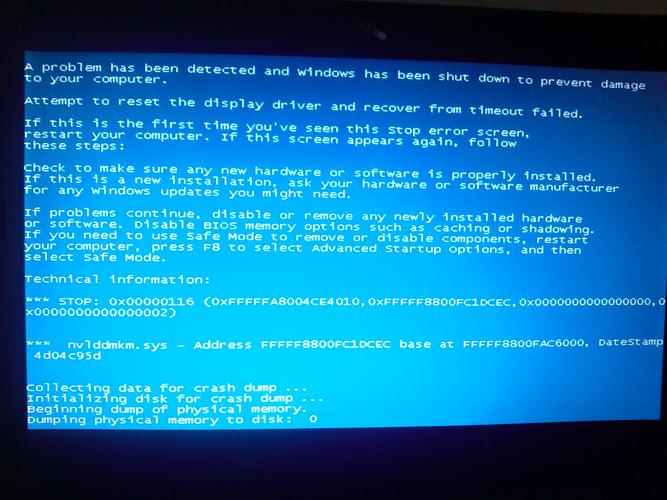

服务器死机是指服务器在运行过程中突然无法响应任何请求,停止工作的状态,这种情况对线上服务的影响尤其严重,可能导致数据丢失和服务中断,给企业带来经济损失和品牌信誉的损害,了解造成服务器死机的原因并采取预防措施是每一个运维工程师的重要职责,下面将详细介绍服务器死机的主要原因,并提供相应的解决方案。
硬件故障
硬件故障是导致服务器死机的一个常见原因,包括但不限于内存条、硬盘、主板等关键部件的损坏或功能异常,这类问题通常需要通过更换故障硬件来解决,定期的硬件检测和维护可以有效预防此类问题的发生。
软件问题
软件问题包括操作系统的错误、应用程序的崩溃或系统文件的损坏,这些问题可能由于软件设计上的缺陷或者是不当的操作引起,更新和打补丁、定期检查系统日志及应用的稳定性是防止软件问题的有效方法。
网络问题
不稳定的网络连接或遭受网络攻击也可能导致服务器死机,大规模的DDoS攻击可能会使服务器资源耗尽而宕机,确保网络设备的稳定性和实施有效的网络安全策略对于预防此类问题至关重要。
负载过大
当服务器承载的工作量超过其处理能力时,也可能引发死机,这通常是由于用户请求过多或数据处理任务过重造成的,优化服务器配置,合理分配和调度任务,以及使用负载均衡技术可以减轻单台服务器的压力。
内存和磁盘问题
内存泄漏或磁盘空间不足也是常见的死机原因,内存泄漏会导致可用内存逐渐减少,最终影响系统运行;而磁盘空间不足则可能导致系统无法写入关键数据,定期检查系统内存使用状态和清理磁盘空间,是确保服务器稳定运行的必要措施。
软件冲突
服务器上安装的软件如果存在冲突,也可能导致系统死机,不同软件间可能存在资源占用冲突或兼容性问题,合理规划软件部署并进行充分的测试,可以避免这类问题发生。
服务器死机的原因多种多样,涉及硬件、软件、网络等多个方面,作为运维工程师,需要对这些潜在问题有所了解,并采取相应的监测与预防措施,通过定期维护和及时的问题处理,可以显著降低死机事件的发生频率,保障服务器的稳定运行。
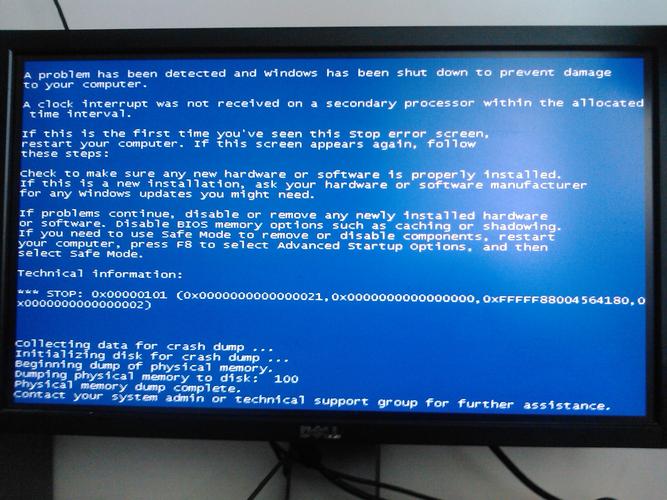
相关问答FAQs
服务器死机应该如何排查?
首先应查看系统日志,如Linux系统中的/var/log/kern.log、/var/log/syslog以及/var/log/messages等,分析死机前后的日志记录,确定死机的可能原因,可以通过last和reboot命令检查系统的重启历史和登陆情况,辅助定位问题发生的时间点。
如何预防服务器死机?
预防措施包括:1. 定期进行硬件检测和维护,避免因硬件故障导致的死机;2. 保持操作系统和应用软件的更新,及时打补丁修复已知漏洞;3. 实施网络安全防护措施,防止网络攻击;4. 监控服务器的负载和资源使用情况,适时进行优化和调整;5. 定期检查系统日志,及时发现并处理潜在问题;6. 进行内存和磁盘空间的监控,确保系统资源充足。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/860129.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复