

使用TensorFlow训练神经网络

TensorFlow是一个流行的开源机器学习框架,用于构建和训练神经网络,我们将介绍如何使用TensorFlow搭建神经网络。 我们将从基本概念和原理入手,一步步构建一个简单的神经网络,并训练它来进行图像分类任务,我们还将探讨如何优化网络性能,使用Dropout进行正则化以防止过拟合,并使用批量标准化加速训练过程,我们将展示如何将训练好的模型应用于新的数据集,以进行预测。
1、TensorFlow介绍
定义与功能:TensorFlow 是由Google开发的开源机器学习框架,支持多种类型的神经网络构建和训练,该平台功能强大,支持从简单的线性模型到复杂的深度学习架构。
环境配置:安装TensorFlow前需确保Python环境正确,可通过Anaconda进行管理,使用Pip安装TensorFlow是最直接的方法,也支持GPU加速版本的安装。
2、搭建第一个神经网络
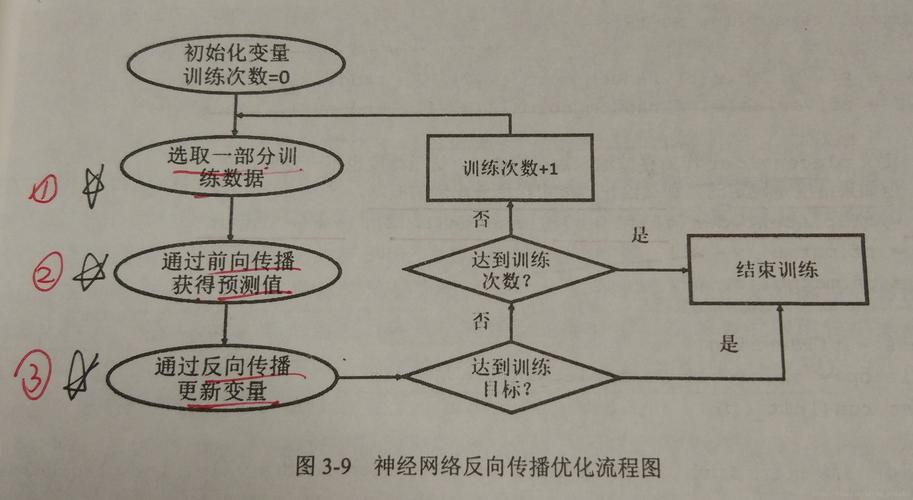
基本结构:神经网络由输入层、隐藏层和输出层组成,每层包含多个节点,每个节点是一个简单的计算单元。
工具与简化:TensorFlow提供tf.keras模块,可以大大简化网络的搭建过程,使用Sequential模型可以快速堆叠各层。
3、数据预处理
数据加载:使用TensorFlow的tf.data API可以有效地加载和预处理数据,这个API支持数据的批处理、洗牌和增强等操作。
数据标准化:通常需要对输入数据进行标准化处理,使其平均值为0,标准差为1,这有助于模型训练的收敛。
4、模型优化
梯度下降:通过最小化损失函数来优化模型参数,TensorFlow提供了多种优化器如SGD、Adam等。
学习率调整:学习率是训练过程中一个重要的超参数,影响模型的学习效率和效果,使用学习率衰减可以改善训练过程。
正则化:为了防止模型过拟合,常见的做法是在损失函数中加入正则化项如L1和L2正则化。
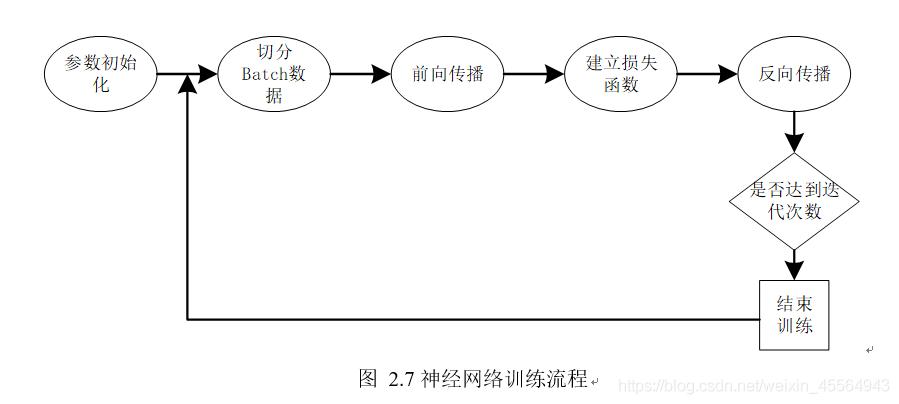
Dropout:在训练过程中随机关闭一部分神经元,可以有效防止过拟合,提高模型的泛化能力。
5、模型评估与应用
模型评估:使用测试数据集评估模型性能,常用的评估指标包括准确率、召回率和F1分数等。
模型应用:训练好的模型可以保存下来,用于实际应用中的预测任务,TensorFlow提供了保存和恢复模型的接口。
归纳而言, 使用TensorFlow训练神经网络涉及多个步骤,包括数据预处理、模型构建、训练优化以及模型评估和应用,通过实践这些步骤,可以掌握使用TensorFlow进行深度学习的基本技能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/859805.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复