


MapReduce是一种编程模型,用于处理和生成大数据集。它分为两个阶段:Map阶段对数据进行过滤和排序,而Reduce阶段则负责将结果汇总。在实际应用中,MapReduce不输出任何内容,因为它的主要目的是处理数据并生成键值对形式的中间结果,这些结果随后可以用于进一步的分析或存储。
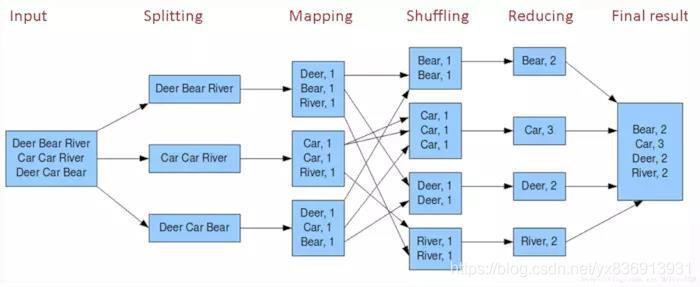
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对(keyvalue pair),在Reduce阶段,所有具有相同键的值被组合在一起,并应用一个归约函数来生成最终结果。

(图片来源网络,侵删)
有时候我们可能不希望MapReduce输出所有的键值对,而是只输出特定的键值对,这种情况下,我们可以使用过滤器来实现这个目标。
以下是一个简单的例子,演示如何使用过滤器来过滤MapReduce的输出:
假设我们有一个文本文件,其中包含一些单词及其出现次数,我们希望只输出出现次数大于某个阈值的单词及其次数。
1、我们需要定义一个Mapper类,它将读取输入文件中的每一行,并将每一行的单词作为键,出现次数作为值。
class WordCountMapper:
def map(self, key, value):
words = value.split()
for word in words:
yield (word, 1) 2、我们需要定义一个Reducer类,它将接收Mapper输出的所有键值对,并对具有相同键的值进行累加。
class WordCountReducer:
def reduce(self, key, values):
total_count = sum(values)
if total_count > threshold:
yield (key, total_count) 3、我们需要定义一个驱动程序,它将读取输入文件,将内容传递给Mapper,然后将Mapper的输出传递给Reducer,并输出最终结果。
def main():
# 设置阈值
threshold = 5
# 创建Mapper和Reducer实例
mapper = WordCountMapper()
reducer = WordCountReducer()
# 读取输入文件
with open("input.txt", "r") as file:
# 将文件内容传递给Mapper
map_output = list(mapper.map(None, line) for line in file)
# 将Mapper的输出传递给Reducer
reduce_output = list(reducer.reduce(key, values) for key, values in map_output)
# 输出结果
for key, value in reduce_output:
print(f"{key}: {value}")
if __name__ == "__main__":
main() 在这个例子中,我们使用了一个简单的阈值过滤器来过滤掉出现次数小于等于阈值的单词,你可以根据需要修改阈值或添加其他过滤器来实现更复杂的过滤逻辑。

(图片来源网络,侵删)
(图片来源网络,侵删)
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/859163.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复