


在MySQL数据库中,采样方式主要包括系统随机采样、系统等距采样、聚类采样、分层采样等,而根据特殊字段(值顺序增加或减少)进行均匀采样取数也是一种常见的采样方法,主要通过查看自增字段值是否整除采样间隔数来实现。

核心采样方式:
1、系统随机采样:
这是最简单的采样方法之一,每个数据点都有相同的几率被选中。
随机采样可以通过SQL的RAND()函数实现,适合没有明显顺序或分布的数据。
这种方法方便简单,但可能无法确保样本的代表性,特别是当数据集分布不均时。
2、系统等距采样:
通过选定一个起始点,然后按照固定的间隔选取数据点。
这种方式适合数据分布较为均匀的情况,可以避免随机采样可能带来的样本偏差。
操作可以通过SQL中的LIMIT和OFFSET命令来完成,提高采样效率和结果的一致性。
3、聚类采样:
将相似的数据点分为若干集群,然后从每个集群中选取代表性的数据点。
这种方法适合数据点具有明显群体特征的情况,可以更有效地覆盖数据的多样性。
聚类采样通常需要预处理数据,使用如Kmeans等聚类算法,再进行样本的选择。
4、分层采样:
在整个数据集中,按照一定的规则划分为不同的层,每层内部进行独立采样。
分层可以根据数据的某个关键属性来划分,比如年龄、地理位置等。
这种方法可以确保每个子集都有代表性的样本,使得整体样本更具代表性。
5、均匀采样:
依据自增字段,如ID或时间戳,进行有规律的采样。
核心逻辑是判断自增字段的值是否能被采样间隔数整除。
适用于数据插入顺序与时间线一致,且业务上需要按照时间序列分析的场景。
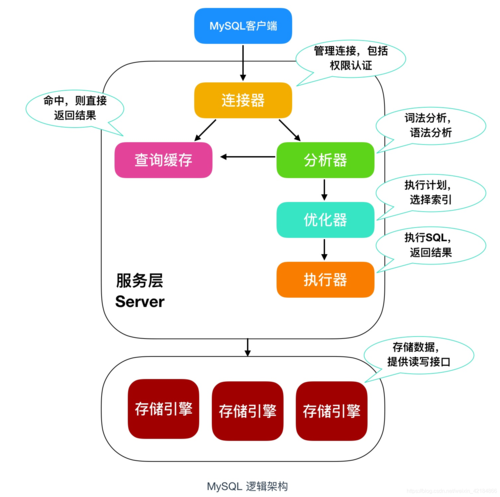
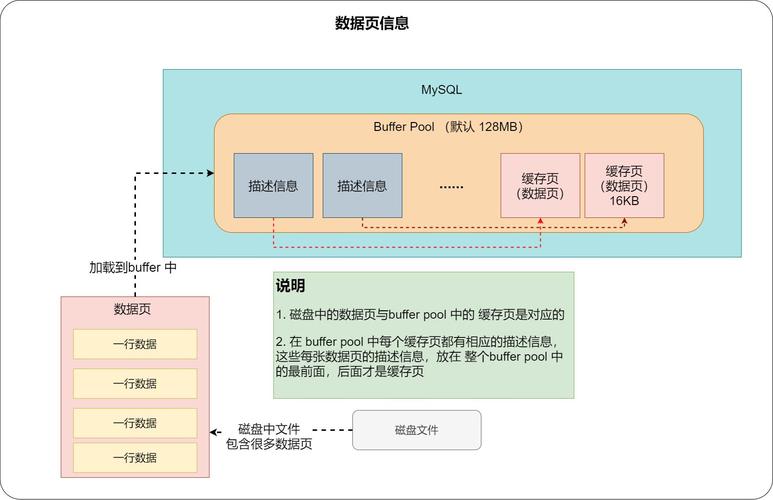
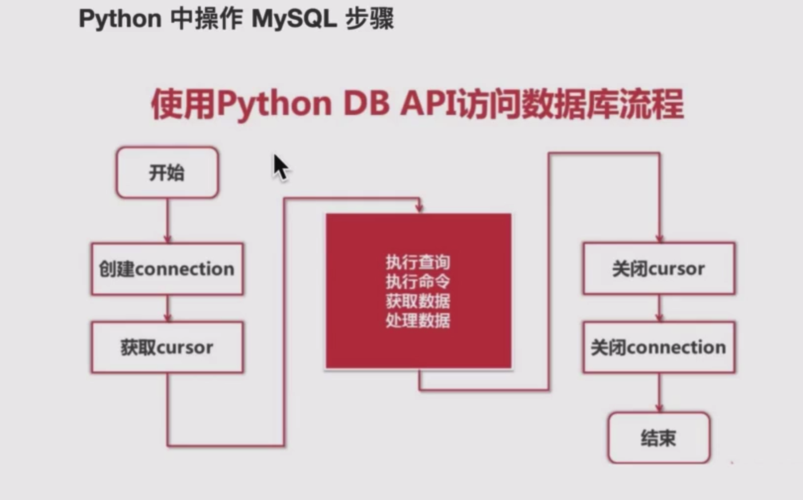
1、统计信息:
MySQL通过采样生成统计信息,帮助优化查询的执行计划。
表的记录数、索引的page个数、字段的Cardinality等都是重要的统计信息,影响查询性能。
2、数据一致性校验:
数据同步过程中,采样用于一致性校验,确保复制数据的准确性。
特别在大数据环境下,采样能有效快速地定位数据异常,提升数据处理的可靠性。
了解并选择合适的采样方法对于保证数据分析工作的准确性和效率至关重要,每种方法都有其适用场景和优缺点,合理运用可以大幅提高数据处理的效率和质量。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/858968.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复