


MapReduce是一种编程模型,用于处理和生成大数据集,在MapReduce中,数据被分成多个分区,每个分区由一个Map任务处理,然后由Reduce任务进行汇总,分区的数量对于优化性能非常重要,因为它决定了并行处理的程度。


设置分区数量
在Hadoop MapReduce中,可以通过以下方式设置分区数量:
1、默认分区数: Hadoop默认使用文件的大小来决定分区数,每个分区的大小约为128MB。
2、手动设置分区数: 可以在提交作业时通过D mapreduce.job.maps参数来手动设置Map任务的分区数。
“`bash
hadoop jar myJob.jar MyDriver D mapreduce.job.maps=10 inputPath outputPath
“`
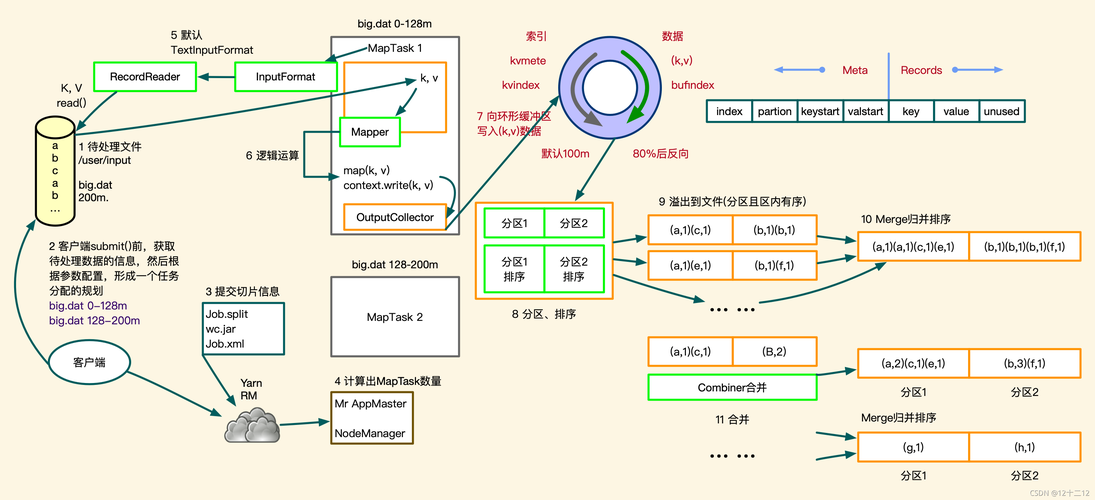
3、基于键值对的分区策略: 可以自定义分区策略,以便根据键值对的不同范围将数据分配到不同的分区,这可以通过实现Partitioner接口并覆盖其getPartition()方法来完成。
变更分区数量
要变更分区数量,可以按照以下步骤操作:
1、增加分区数量: 增加分区数量可以提高并行度,从而加快处理速度,但请注意,过多的分区可能会导致资源过度分配或调度开销增加。
2、减少分区数量: 减少分区数量可以减少并行度,从而降低资源消耗,如果分区数量过少,可能会导致某些节点负载过高,而其他节点闲置。
3、动态调整分区数量: 在某些情况下,可能需要根据数据量和集群资源动态调整分区数量,这可以通过监控作业进度和资源利用率来实现,并根据需要动态调整分区数量。
示例代码
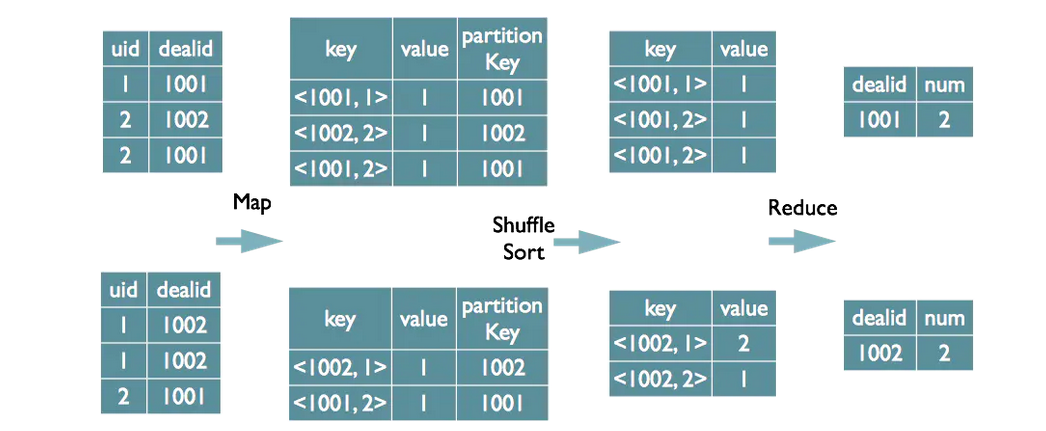
以下是一个简单的Java代码片段,展示了如何自定义分区策略:
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
public class CustomPartitioner extends Partitioner<Text, Text> {
@Override
public int getPartition(Text key, Text value, int numPartitions) {
// 根据key的值决定分区号
if (key.toString().startsWith("A")) {
return 0; // 分区0
} else if (key.toString().startsWith("B")) {
return 1; // 分区1
} else {
return 2; // 其他情况,分区2
}
}
} 在这个例子中,我们根据键的前缀将其分配到不同的分区,这只是一个简单的示例,实际应用中可以根据需求编写更复杂的分区策略。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/858870.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复