


我将详细介绍如何处理拥有100万条记录的MySQL数据库,涵盖从数据库结构设计、数据插入、性能优化到高级查询技巧等方面,这种规模的数据量虽然挑战性强,但通过合理的数据库管理和优化措施,可以有效提升数据处理效率和查询速度。

数据库设计基础
表结构设计
数据类型选择:选择合适的数据类型对优化数据库性能至关重要,使用INT类型代替VARCHAR类型来存储整数。
索引策略:合理设置索引可以显著提高查询效率,通常情况下,应该为主键以及频繁用于搜索的列创建索引。
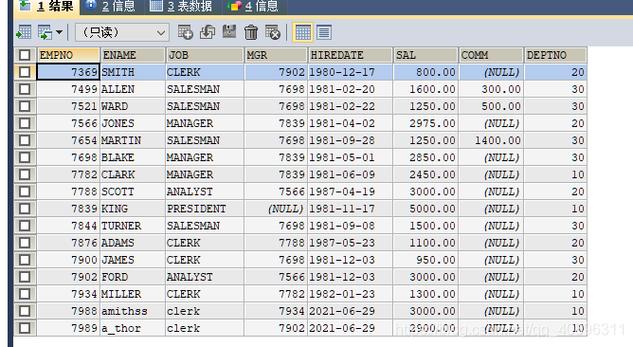
创建测试数据表
USE db_xk;
DROP TABLE IF EXISTS tb_test;
CREATE TABLE tb_test (
id INT AUTO_INCREMENT PRIMARY KEY,
data VARCHAR(255) NOT NULL
); 此SQL语句首先选择了数据库db_xk,然后创建一个名为tb_test的表,其中包含一个自动递增的整数型主键id和一个可存储255个字符的data字段。
数据插入与管理
快速数据插入
1、批量插入:使用批量插入命令可以大幅提升数据插入速度,一次插入多行数据而非循环插入每行数据。
2、事务处理:尽量减少事务的频繁提交,可以通过设置较大的事务或者关闭自动提交来加快插入速度。
高效数据管理
定期维护:定期对数据库进行优化,如更新统计信息、重建索引等,保持数据库的良好性能。
分区表:对于非常大的表,可以考虑使用分区技术将表分成小部分,分散存储在不同的物理位置,以提高访问速度和管理效率。
性能优化
索引优化
覆盖索引:设计索引时应尽量实现覆盖索引,即索引包含了所有查询所需的字段,这样数据库引擎可以通过索引直接获取所需数据,减少对实际数据行的访问。
引擎选择
InnoDB vs MyISAM:InnoDB和MyISAM是MySQL的两种存储引擎,InnoDB支持事务处理,更适合处理大量数据时的一致性和完整性要求,而MyISAM在读密集型场景下表现更好,尤其是在执行COUNT(*)操作时更为高效。
高级查询技巧
查询优化
分析查询计划:通过EXPLAIN命令分析查询的执行计划,找出慢查询的根本原因,并针对性地进行优化。
避免全表扫描:尽量写出能够利用到索引的查询语句,避免全表扫描,特别是在数据量大的情况下。
系统配置调整
内存优化:调整MySQL的配置,如增加innodb_buffer_pool_size可以提高InnoDB存储引擎的性能。
查询缓存:适当启用查询缓存功能,可以避免重复执行相同的查询,节省查询时间。
通过上述详细讨论,我们可以看到,处理大规模MySQL数据库涉及多个方面,包括合理设计数据库架构、快速插入数据、优化查询及系统性配置调整等,每个环节都需要精心设计和优化,以确保数据库能够高效地处理达到百万级别的数据量,随着技术的发展,我们还需要不断学习和适应新的数据库管理和优化技术,以应对不断变化的技术需求和挑战。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/858534.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复