


在当今互联网时代,爬虫与CDN(内容分发网络)是两个经常被提及且关系紧密的技术,它们在信息获取、数据处理和内容加速等方面发挥着重要作用,以下是对爬虫和CDN的详细解析:


爬虫
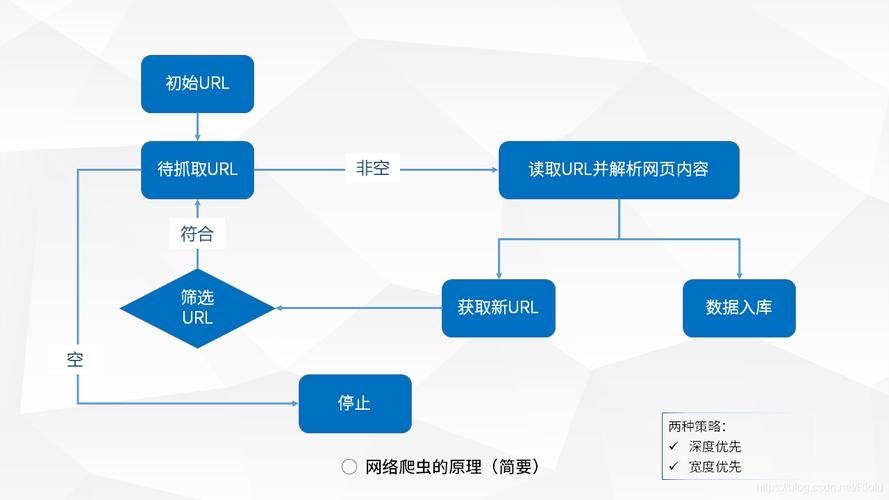
1、定义:爬虫是一种自动访问Web资源的应用程序,其主要功能是批量获取网站信息,这种技术手段可以被用来收集各种在线数据,如同不知疲倦的蚂蚁,在网络世界中不停奔走,抓取所需数据。
2、工作原理:爬虫通常通过发送HTTP请求到Web服务器,获取页面内容,然后解析这些内容,抽取有价值的数据,这个过程可以自动化,以遍历大量网页,实现信息的大规模采集。
3、应用场景:从搜索引擎的页面索引到数据分析,再到市场价格监控,爬虫的应用场景极其广泛,它们是现代以及未来获取信息的关键工具之一。
4、反爬虫策略:为了防止爬虫造成的信息泄露或服务器负载过重,许多网站会部署反爬虫机制,这包括检测访问者的IP地址、请求频率、UserAgent等,以识别并阻止自动的批量请求。
CDN
1、定义:CDN是一个由一系列分布式服务器构成的网络,旨在通过将网站内容缓存在全球各地的边缘节点,来提高用户访问速度和网站性能。
2、工作机制:当用户请求一个网站时,CDN会将请求引导至最近的边缘节点,从而减少数据传输时间和延迟,这个过程中,源站的数据被缓存在边缘节点,无需每次都通过复杂的网络回到源服务器获取数据。
3、主要优势:CDN不仅可以显著提高网站加载速度,还可以减少源站的带宽需求,降低因流量激增导致的宕机风险,进而提升用户体验。
4、与爬虫的关系:CDN可以用来识别和阻止来自特定爬虫的请求,例如通过设置UserAgent黑白名单来防止恶意爬虫访问CDN资源。
随着互联网技术的发展,爬虫技术和CDN服务都在不断进步,爬虫变得更加高效、智能,CDN服务也在不断优化其边缘节点的分布和缓存策略,以更好地应对日益增长的数据和访问需求,两者之间形成了一种既竞争又合作的关系,共同推动着互联网的发展。
理解爬虫和CDN的工作原理及其相互之间的关系,对于任何希望有效利用这些技术的组织或个人都至关重要,无论是为了保护数据安全,还是为了提升用户体验,正确配置和使用这些技术都是关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/857327.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复