


在MapReduce框架中,处理大规模数据集时,经常需要将输出结果存储到多个目录中,以便于后续的数据检索和处理,下面将深入探讨如何在Hadoop MapReduce中实现多目录输出,并遵循一定的模型输出目录规范:


1、Hadoop MultipleOutputs的基本使用
基本概念:MultipleOutputs是Hadoop MapReduce框架提供的一个功能,允许开发者将数据写到多个输出文件中。
输出文件命名:使用MultipleOutputFormat类,可以自定义输出文件的名称,这些名称可以基于输出的键和值或任意字符串。
2、关键类和API
FileInputFormat和FileOutputFormat:这两个类用于设定MapReduce作业的输入和输出路径。
MultipleOutputs类:整合了旧版中MultipleOutputs和MultipleOutputFormat的功能,提供了更多的灵活性在输出格式上。
3、输出目录结构设计
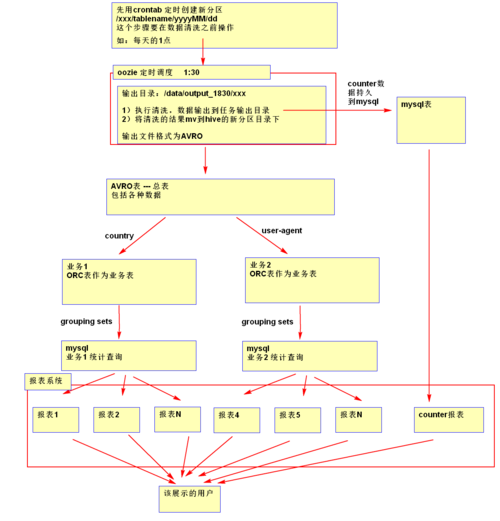
按作业类型划分:根据不同的MapReduce作业类型(如数据处理、数据分析等),在输出目录下创建子目录。
时间戳命名:每个目录可以包含时间戳,以区分不同运行时间的作业输出。
4、目录命名规范
规范化命名:输出目录应使用清晰的命名方式,例如<jobtype>_<timestamp>。
避免特殊字符:目录名应避免使用特殊字符,以免造成命令行操作的不便。
5、数据管理和维护
定期清理策略:为防止输出目录无限增长,应设定数据的保存期限,并进行定期清理。
备份与恢复:重要数据需进行备份,并提供可靠的恢复机制,确保数据的持久性和可靠性。
6、安全性与权限
访问控制:根据需要对输出目录设置合适的访问权限,保护敏感数据不被未授权访问。
用户隔离:在多用户环境下,应为不同用户的作业输出设置独立的目录,确保数据隔离。
通过上述详细分析,可以看出在Hadoop MapReduce中实现多目录输出需要考虑多个方面,包括输出格式的设计、目录结构的合理规划、数据维护策略以及安全性措施,正确实施这些策略不仅能提高数据处理的效率,还能保障数据的安全性和可维护性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/857146.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复