


在探讨MongoDB中的MapReduce功能时,需要理解其基本概念与执行过程,MapReduce是一种计算模型,适用于处理和聚合大量数据,尤其在分布式数据库环境中表现出色,MongoDB作为一款流行的NoSQL数据库,通过整合MapReduce功能,为用户提供了强大的数据分析能力,具体分析如下:

1、MapReduce的基本概念
核心思想:MapReduce的核心在于将复杂的运算任务分解为可独立运行的小块(Map阶段),之后再将各部分的结果合并起来形成最终结果(Reduce阶段)。
在MongoDB中的作用:在MongoDB中,MapReduce主要被用来进行大规模的数据聚合操作,例如类似SQL中的Group By操作,它能够有效地处理海量数据集,非常适合于数据分析和报告生成。
2、MongoDB中MapReduce的执行阶段
Map阶段:在这一阶段,Map函数会被应用到集合的每一个文档上,开发者可以定义函数中如何生成键值对,这些键值对将被发送到下一个阶段。
Shuffle阶段:这一阶段是过渡阶段,MongoDB会将Map阶段生成的键值对根据键进行分组,形成列表,并把它们分配给对应的Reduce函数处理。
Reduce阶段:在此阶段,Reduce函数会汇总所有具有相同键的值,生成一个更小的、汇总后的结果集。

Finalize阶段:这是可选的阶段,用于在获得最终结果后进一步处理数据,比如清理或修饰结果集中的数据。
3、使用案例分析
案例描述:假设有一个电商订单系统,需要统计每个客户的总订单金额,这个操作涉及对大量订单数据的处理和聚合。
实施步骤:可以在orders集合上执行MapReduce操作,通过query筛选状态为“A”的订单,在map操作中,将当前文档的客户ID(this.cust_id)和订单金额(this.amount)作为键值对发射出去,具有相同客户ID的订单金额将自然被归组到一起,进而在reduce阶段进行总和计算。
4、MapReduce的灵活性与优势
并行处理:MapReduce能够将运算任务分发到多个服务器上并行处理,有效利用集群的计算资源,提高数据处理速度。
易于扩展:由于其天生的分布式特性,MapReduce可以轻松扩展以处理更大的数据集或更复杂的运算任务,只需增加更多的计算节点即可。
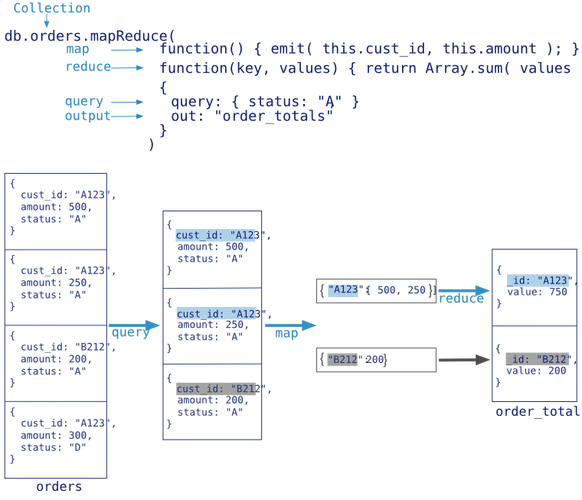
可以看出MongoDB中的MapReduce不仅提供了一种高效处理大规模数据集的方法,还带来了良好的灵活性和可扩展性,通过合适的设计和实现,可以最大化地发挥其潜力,解决各种复杂的数据分析需求。
MongoDB的MapReduce是一个功能强大的工具,尤其适合于处理和分析大规模数据集,通过了解其基本工作原理和实际操作方法,开发者可以更有效地进行数据分析,从而支持数据驱动的决策制定。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/856135.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复