


MapReduce Shuffle过程详解
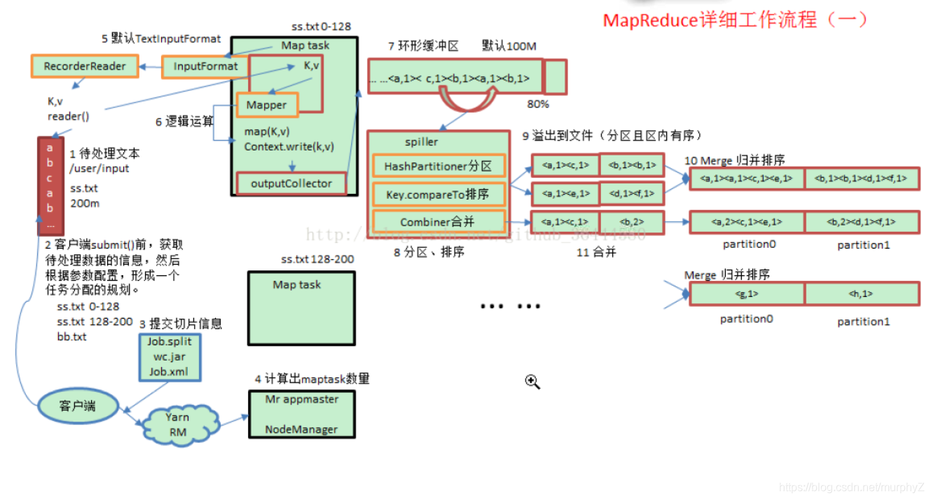

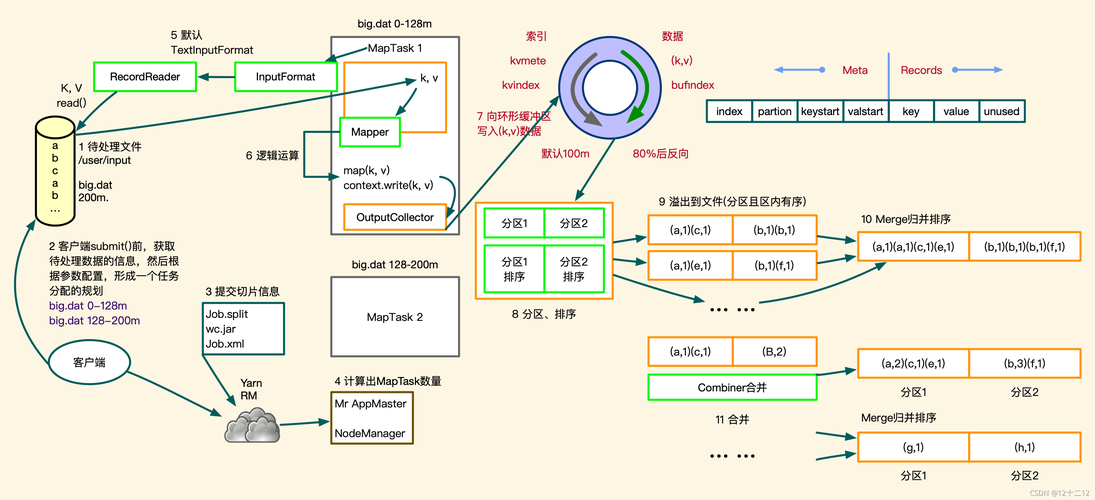
MapReduce的Shuffle过程是MapReduce模型中极为关键的一环,它负责将Map任务的输出数据传输到Reduce任务,以便做进一步处理,这一过程涉及的关键步骤包括分区、排序、和数据传输。
Map端的Shuffle过程:
1、数据分区:在Map任务完成数据处理并输出后,系统会将数据分成多个区(partition),每个分区对应一个Reduce任务,分区的过程通常通过计算数据键(key)的哈希值,并对Reduce任务的数量取模来实现。
2、排序:每个分区内的数据按键(key)进行排序,默认情况下,系统采用升序排列,这是为了提高后续处理效率并减少数据处理复杂度。
3、数据写入磁盘:排序完成后,每个分区的数据会被写入到本地磁盘,这一步是为了确保数据可以在Map任务和Reduce任务之间稳定传输,即使任务失败也可以从磁盘中恢复数据。
Reduce端的Shuffle过程:
1、数据拷贝:Reduce任务开始时,它会从各个Map任务节点拉取相应分区的数据,这个过程可能涉及到网络传输,因此是性能调优的一个重要考虑点。

2、合并数据:为了提高效率,系统可能会对拉取的数据进行合并操作,以减少后续处理的数据量。
3、数据处理:数据全部拉取和整合完成后,Reduce任务开始根据业务逻辑处理这些数据,并最终输出结果。
Shuffle过程的性能考量:
内存使用:在Map任务输出数据时,合理设置内存缓冲区大小可以有效减少磁盘IO操作,提高性能。
网络带宽:数据在Map任务和Reduce任务间传输时,网络带宽成为潜在的瓶颈,适当调整数据传输参数,如增加并行度,可以提升数据传输效率。
磁盘IO:由于Map任务需要将数据写入磁盘,Reduce任务也需要从磁盘读取数据,优化磁盘操作的效率是提升整体性能的关键。
了解和优化MapReduce中的Shuffle过程对于提高大数据处理效率具有重要意义,通过适当的配置和调优,可以显著提升数据处理速度和减少资源消耗,这对于处理大规模数据集来说尤其重要。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/855962.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复