


MapReduce是一个分布式运算程序的编程框架,它允许用户开发基于Hadoop的数据分析应用,下面将详细解析如何搭建MapReduce环境,并通过小标题和单元表格的方式,使信息呈现更为清晰:
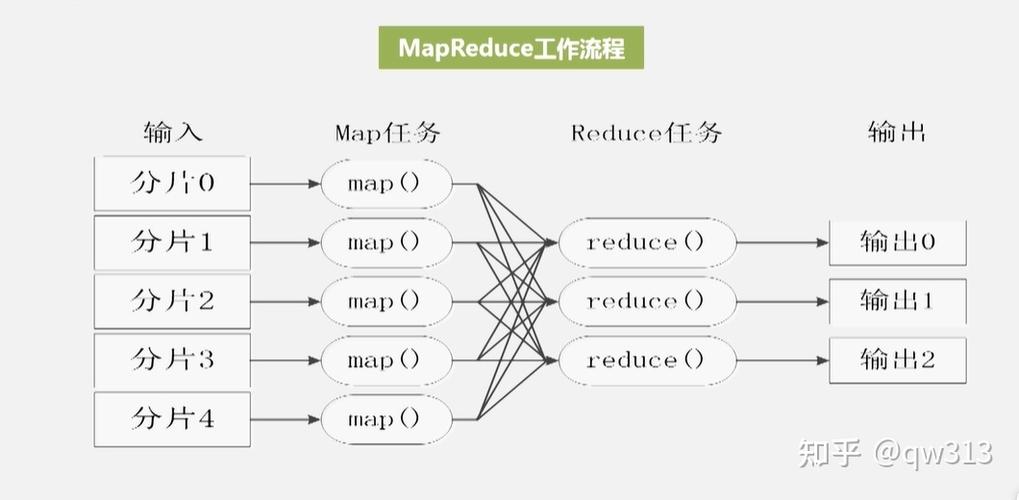

1、理解MapReduce
概念与思想:MapReduce是一种处理大规模数据集的编程模型,它将计算过程分为两个阶段:Map和Reduce,在Map阶段,系统将数据分成多个块,并行处理;在Reduce阶段,系统将Map的结果汇总,得到最终结果。
模拟实现分布式计算:通过模拟实现来深入理解分布式计算的概念,包括数据的分发、并行处理和结果汇总等步骤。
与分布式并行计算区别:理解MapReduce与传统分布式并行计算之间的差异,例如任务切分、数据本地化处理等特点。
2、搭建Hadoop环境
下载与安装:获取Hadoop安装包,解压到合适的目录,并设置必要的环境变量以便于命令行操作。
配置环境变量:编辑~/.bashrc或~/.profile文件,添加Hadoop的bin目录到系统的PATH变量中。
验证安装:通过运行hadoop version来检查Hadoop是否安装正确,确保能够输出正确的版本信息。
3、Hadoop任务封装
使用jar包:在Hadoop中,任务通常被打包成jar文件,这样可以方便地部署和运行。
编写MapReduce程序:使用Java等支持的语言编写MapReduce程序,然后编译并打包成jar文件。
任务配置:通过配置文件设定MapReduce任务的各种参数,如输入输出路径、Mapper和Reducer类等。
4、MapReduce流程细分
数据读取:利用TextInputFormat和LineRecordReader从HDFS读取数据文件。
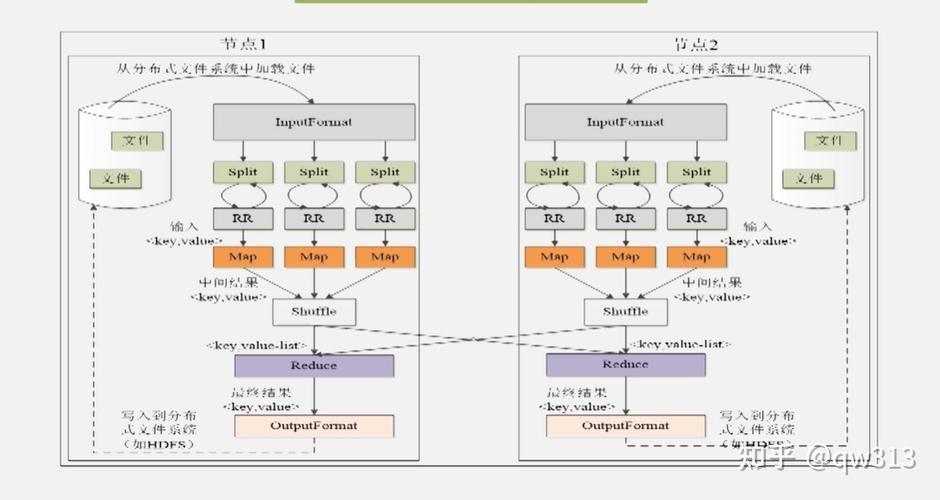
数据分片:将数据文件切分成若干个小数据块(Splits),以便并行处理。
执行Mapper:每个数据块由一个Map任务处理,执行用户定义的Map函数。
Shuffle:对Map的输出进行排序、分区和传输,为Reduce阶段准备数据。
执行Reduce:执行用户定义的Reduce函数,整合Map的结果,并输出最终结果。
5、编程实践
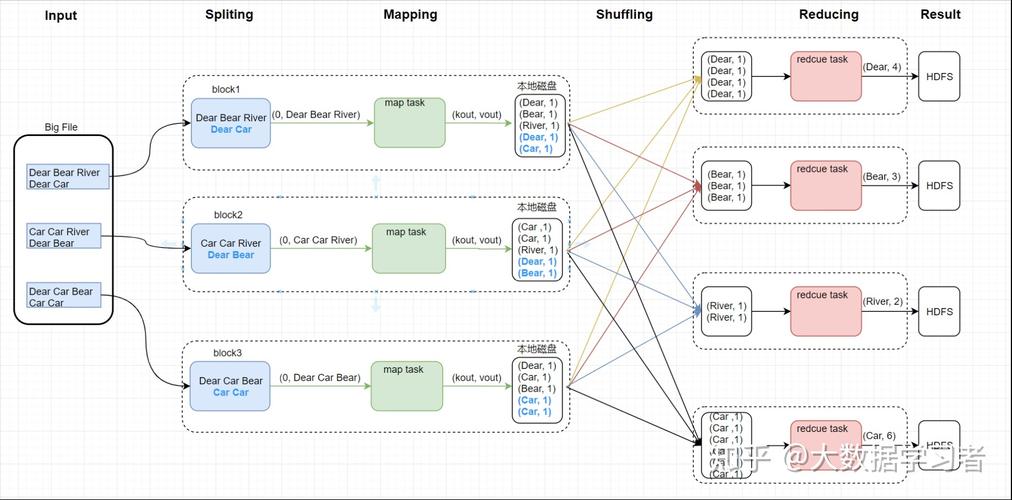
WordCount案例分析:学习经典的WordCount示例,了解如何使用MapReduce框架进行词频统计。
代码编写:实际编写Mapper和Reducer的代码,掌握代码结构和编程技巧。
程序调试:运行程序并进行调试,确保程序能正确处理数据并产生预期结果。
为了更直观地呈现相关信息,下面提供了一个有关Hadoop环境搭建的简要步骤表格:
| 步骤号 | 步骤说明 | 关键操作 | 备注 |
| 1 | 下载Hadoop安装包 | 访问官方网站下载合适版本的Hadoop | 选择合适的版本,根据操作系统类型选择安装包 |
| 2 | 解压安装包并设置环境变量 | 解压到指定目录;编辑~/.bashrc添加变量 | 环境变量包括Hadoop的bin目录 |
| 3 | 验证安装 | 运行hadoop version | 确保安装成功,能够看到版本信息 |
| 4 | 编写MapReduce程序并打包成jar文件 | 编写、编译、打包 | 使用IDE进行Java程序开发 |
| 5 | 配置MapReduce任务 | 编辑配置文件 | 设定任务参数,如输入输出路径、Mapper和Reducer类 |
| 6 | 运行MapReduce任务 | 使用hadoop jar命令运行 | 在Hadoop集群上执行任务 |
可以发现搭建MapReduce环境涉及到对MapReduce概念的理解、环境的搭建、任务的配置以及编程实践等多个环节,每一个步骤都是构建稳定可靠数据处理系统的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/855028.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复