


MapReduce分组(Grouping)是Hadoop框架中的一个重要概念,它允许将具有相同键值的键值对组合在一起,这个过程在Map阶段和Reduce阶段之间进行,通常被称为Shuffling。
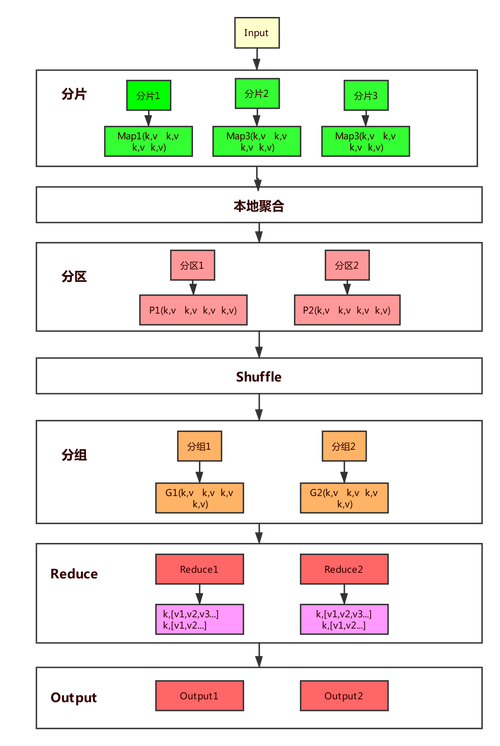

以下是关于MapReduce分组的详细解释:
1、分组的目的
分组的目的是将具有相同键值的键值对组织在一起,以便在Reduce阶段进行处理,这样可以减少数据传输量,提高处理效率。
2、分组的过程
分组的过程包括以下步骤:
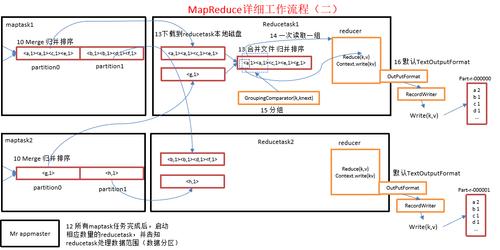
在Map阶段完成后,每个Map任务输出的键值对被写入到磁盘上的临时文件中。
这些临时文件根据键值进行排序,使得具有相同键值的键值对相邻。
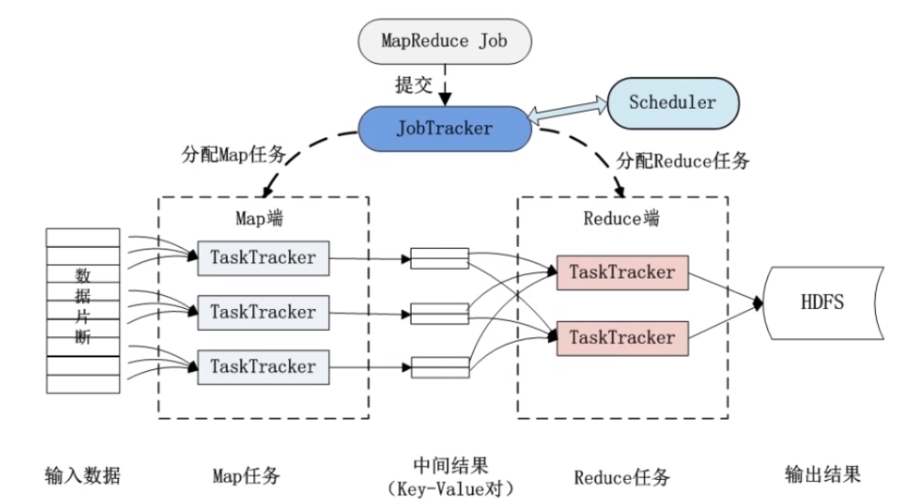
将这些排序后的文件进行合并,将具有相同键值的键值对组合在一起。
将合并后的数据发送给Reduce任务进行处理。
3、分组的实现
分组的实现通常由Hadoop框架中的Shuffle和Sort组件来完成,Shuffle负责将Map任务的输出数据发送给Reduce任务,而Sort组件负责对数据进行排序和分组。
4、分组的优点
分组的优点包括:
减少数据传输量:通过将具有相同键值的键值对组合在一起,减少了数据传输量,提高了处理效率。
负载均衡:分组可以将数据均匀地分配给不同的Reduce任务,实现负载均衡。
容错性:如果某个Reduce任务失败,只需要重新执行该任务即可,不需要重新执行整个作业。
MapReduce分组是将具有相同键值的键值对组合在一起的过程,它在Map阶段和Reduce阶段之间进行,目的是减少数据传输量、实现负载均衡和提高容错性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/854621.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复