


"UserAgent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36" }

2、验证码. 输入验证码才能继续浏览网站,常用于注册、登录、评论等操作。 解决方法:OCR技术或手动输入。 3、封IP. 一段时间内限制访问次数,超过则封锁IP地址。 解决方法:更换IP代理。 4、滑块验证. 通过滑动滑块完成验证,常见于各类app注册页面。 解决方法:使用打码平台,或者直接手动滑动。 5、关联请求上下文. 前后两次请求有关联性,需要先完成第一次请求后才能进行第二次请求。 解决方法:按照顺序模拟正常用户的操作流程。 6、JavaScript参与运算. JS脚本参与数据运算,并在前端显示结果,服务器端根据运算结果判断是否为爬虫。 解决方法:分析JS代码,模拟JS运算过程。 7、提高数据获取成本. 增加爬虫的抓取成本,比如降低页面中有用数据的比例,增加无用数据的比例;需要登录才能浏览等。 解决方法:优化自己的爬虫策略,减少无效抓取。
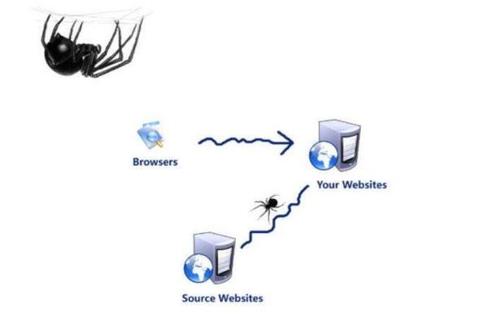
爬虫与反爬虫的斗争已经变成了一场没有硝烟的战争,反爬虫技术不断更新迭代,而爬虫工程师们也在不断寻找突破方法。 在这场战争中,CDN作为网站的一层保护伞,其作用愈发重要。 常见的CDN反爬技术包括referer检测、cookies和session验证、以及各种加密技术。
反爬虫技术概览
1、useragent识别
描述:识别访问者的useragent,区分并阻止来自非浏览器或特定爬虫的访问。
执行难度:低
特点:初级阶段反爬技术,可通过模拟浏览器useragent绕过。
2、验证码
描述:要求访问者输入验证码以证明非自动化工具。
执行难度:中
特点:较为常见,可使用OCR技术或手动输入解决。
3、封IP
描述:对频繁访问的IP进行暂时或永久封锁。
执行难度:中

特点:简单有效,但可能误伤真实用户,爬虫可通过更换IP代理绕过。
4、滑块验证
描述:通过滑动滑块完成的验证机制,确认操作者为真实用户。
执行难度:高
特点:较新的一种验证方式,通常需要手动操作或利用打码平台解决。
5、关联请求上下文
描述:要求请求之间保持一定的上下文关系,如cookie、session等。
执行难度:高
特点:模拟正常用户操作流程可以解决,增加了爬虫的复杂性。
6、JavaScript参与运算
描述:JS脚本参与数据处理,服务器根据运算结果判断请求是否来自爬虫。
执行难度:高
特点:需分析JS代码并模拟其运算过程。
7、提高数据获取成本
描述:通过各种手段增加爬虫抓取成本,如降低数据可获取率、增加访问门槛等。
执行难度:中
特点:对爬虫造成一定阻碍,但难以完全阻止。
CDN反爬技术详解
1、UserAgent检测与控制
操作方式:在CDN配置中设置允许访问的UserAgent列表,拒绝非浏览器或特定爬虫的访问。
应用场景:适用于初级阶段的反爬措施,可有效阻止一部分爬虫的访问。
2、Referer检测
操作方式:检查HTTP请求头部的Referer字段,确保请求来源于可信的网站或路径。
应用场景:适用于图片、文件等资源的防盗链,可以有效避免资源的滥用和直接访问。
3、Cookies和Session验证
操作方式:通过设置和验证cookies与session来确认请求的合法性。
应用场景:适用于需要用户登录才能访问的内容,可以有效筛选出未登录的爬虫请求。
4、加密技术应用
操作方式:利用各种加密技术对请求参数进行加密,增加爬虫解析难度。
应用场景:特别适用于对安全性要求较高的场景,如密码传输、敏感数据处理等,可以有效提升数据安全等级。
CDN作为现代网站架构中不可或缺的组件,不仅能够提供加速服务,还能有效地参与到反爬机制中,为网站数据安全提供一层额外的保护,通过合理配置CDN的反爬机制,可以大大降低非法爬虫的访问频次,保护网站数据不被恶意抓取,随着爬虫技术的不断进步,CDN反爬技术也需要不断更新迭代,以应对更加复杂的爬虫挑战,对于网站运营者而言,了解和运用好CDN的反爬功能,将是保护数据安全的重要一环。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/854475.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复