


MapReduce中的Shuffle过程是连接Map和Reduce阶段的关键环节,它负责对Map输出的数据进行分组、排序,并将数据传输到Reduce端,Shuffle的性能直接影响整个MapReduce作业的执行效率,因此对其进行调优是提高作业性能的重要手段,下面详细探讨MapReduce Shuffle调优的各个层面:
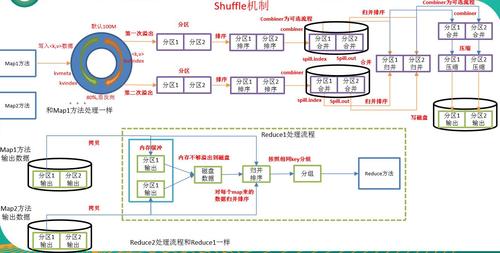

环形缓冲区设置
调整缓冲区大小
默认设置:默认情况下,Map阶段的环形缓冲区大小为100MB。
优化建议:根据具体硬件配置,可以适当增加缓冲区的大小(如调整到200MB),以减少磁盘溢写次数,从而降低IO成本。
磁盘IO优化
减少Spill次数
Spill过程:当Map输出的数据填满环形缓冲区时,需要将其Spill到磁盘上。
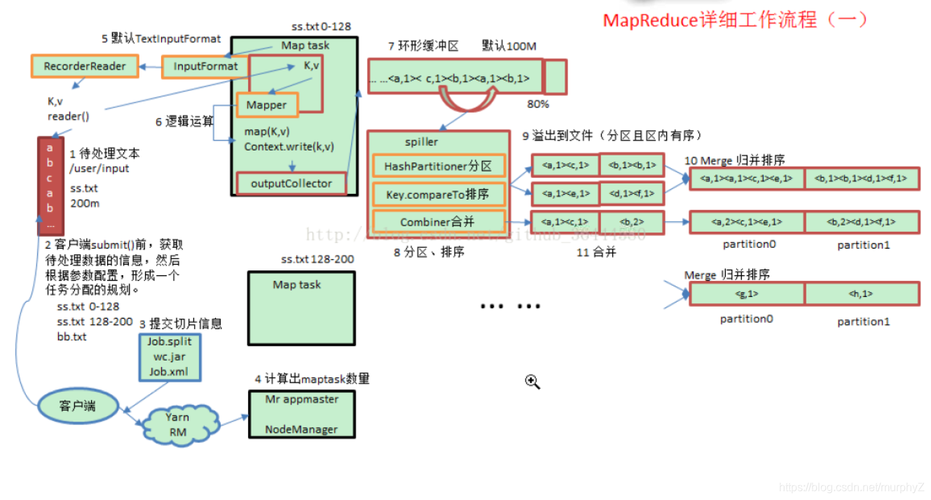
调优策略:通过增加mapreduce.task.io.sort.mb的值,可以增大缓冲区,减少Spill次数,有效降低磁盘IO频率。
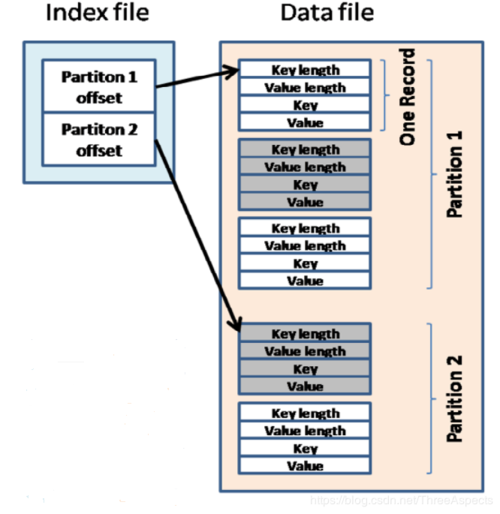
压缩Spill文件
压缩优势:采用Snappy、Lzo等高效的压缩算法,可以在不牺牲太多CPU资源的前提下减少磁盘和网络传输的数据量。
实施步骤:在Map阶段对Spill文件启用压缩,需合理评估压缩与解压缩带来的CPU开销。
网络IO优化
合理分区策略
自定义分区:通过实现自定义的getPartition方法,可以有针对性地解决数据倾斜问题,使得数据在Reduce端更均匀地分布。
提前Combiner操作
Combiner作用:在Map端对输出结果进行局部聚合,减少数据的网络传输量。
适用场景:Combiner适用于求和、最大值等操作,不适用于需要精确保留所有键值对的场景(如求平均值)。
归并操作优化
调整归并参数
默认设置:Hadoop默认会归并10个Spill文件。
优化建议:适当增加归并的文件数(如调整至20个),可以提升归并的效率,降低后续处理的复杂度。
内存管理优化
JVM调优
内存分配:合理设置Map任务的JVM堆大小,确保有足够的内存来处理Map输出的数据。
GC策略:优化垃圾回收策略,避免频繁的Full GC导致的性能抖动。
总体调优策略
综合考量
硬件资源:基于具体的硬件配置(如内存大小、CPU核心数、磁盘I/O能力)进行综合考虑。
作业特性:根据作业的具体需求和数据特点进行有针对性的调优。
测试与调整
基准测试:通过实际运行作业并监测其性能指标(如执行时间、资源利用率等),逐步调整上述参数。
迭代优化:根据测试结果反复调整配置,直至达到最佳性能表现。
MapReduce Shuffle调优是一个涉及内存管理、磁盘IO、网络传输以及数据处理等多个方面的复杂过程,通过对环形缓冲区大小、磁盘IO、网络传输、归并操作等方面的优化,以及对整体策略的综合考量和不断测试调整,可以显著提升MapReduce作业的执行效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/854455.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复